Read More

Developer
Knowledge Center
Empowering engineers with everything they need to build, monitor, and scale real-time data pipelines with confidence.


Release 95.3: Memory leak fix for in-memory compute users
95.3 fixes a memory leak in our in-memory compute implementation, reported by our customers.
Read More
Highlights
Release
January 19, 2026
Release 95.3: Memory leak fix for in-memory compute users
95.3 fixes a memory leak in our in-memory compute implementation, reported by our customers.

Release
January 12, 2026
Release 95.2: quality-of-life improvements across Kpow, Flex & Helm deployments
95.2 focuses on refinement and operability, with improvements across the UI, consumer group workflows, and deployment configuration. Alongside bug fixes and usability improvements, this release adds new Helm options for configuring the API and controlling service account credential automounting.

How-to
December 8, 2025
Integrate Kpow with Oracle Compute Infrastructure (OCI) Streaming with Apache Kafka
Unlock the full potential of your dedicated OCI Streaming with Apache Kafka cluster. This guide shows you how to integrate Kpow with your OCI brokers and self-hosted Kafka Connect and Schema Registry, unifying them into a single, developer-ready toolkit for complete visibility and control over your entire Kafka ecosystem.
All Resources
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.

Release
July 12, 2023
Release 91.5: Expand and Explore
Kpow v91.5 brings improved UX for expanding and exploring tabular data, provides support for importing messages with headers for production, and fixes a few minor bugs.
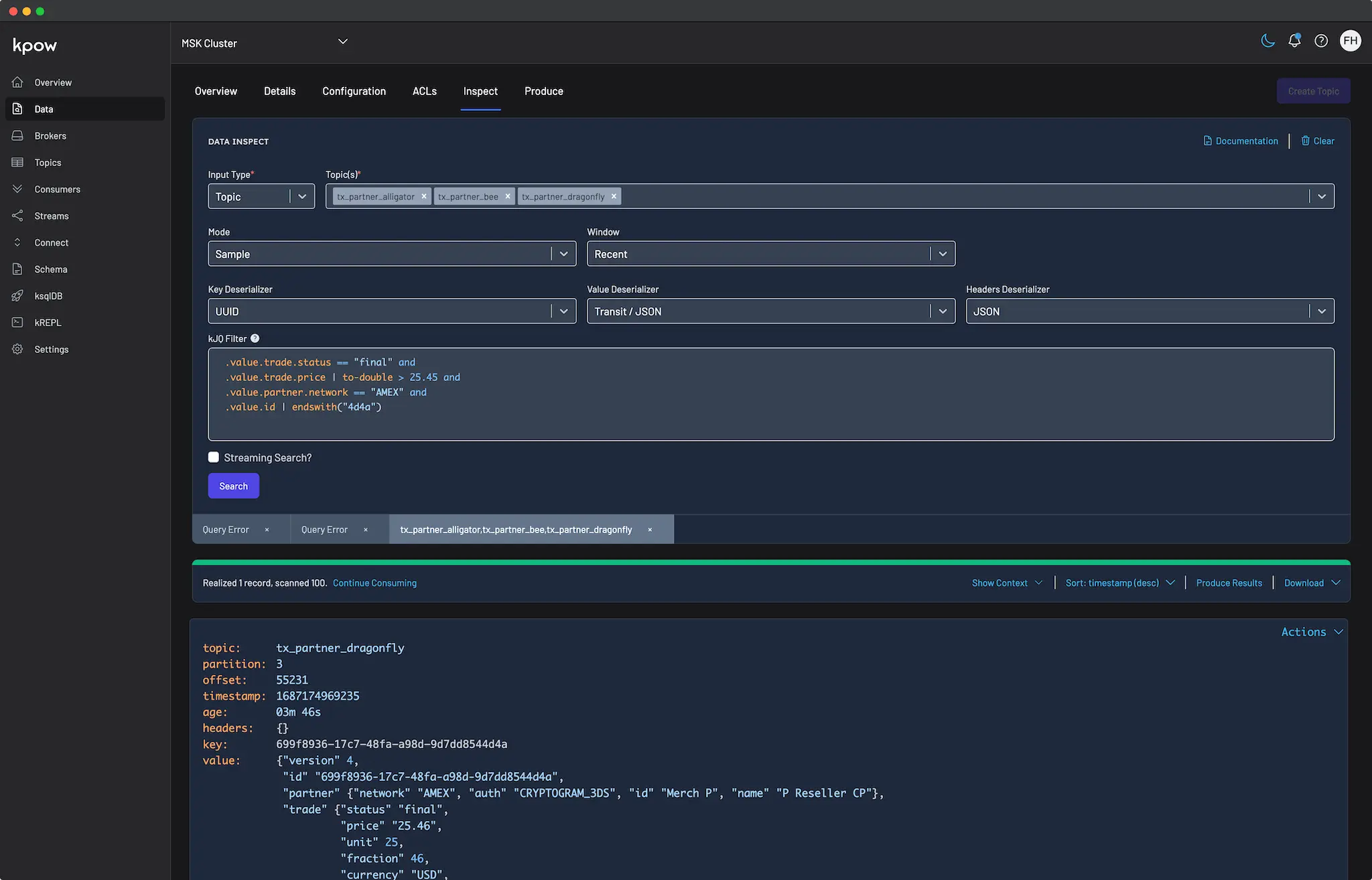
Article
June 20, 2023
Kpow Community Edition 🚀
Kpow Community Edition is a free, developer focused toolkit for Apache Kafka clusters, schema registries, and connect installations.
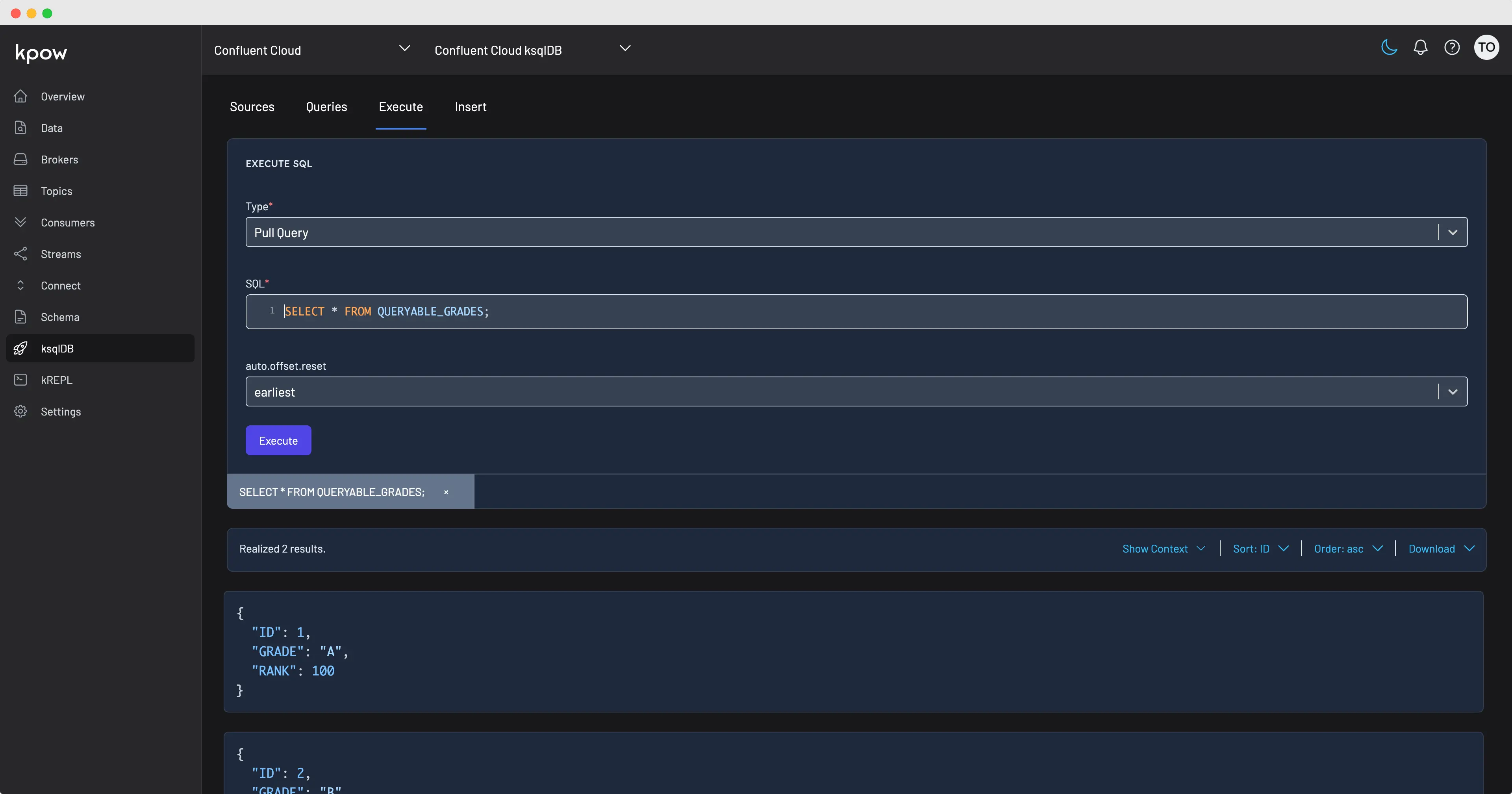
Release
June 6, 2023
Release 91.1: ksqlDB UI and Broker Disk Telemetry
Kpow v91.1 introduces a new ksqlDB UI, new disk usage telemetry, and wildcard filtering.
Release
May 30, 2023
Release 91.4: Graviton Support
Kpow v91.4 introduces ARM64 docker builds to support Graviton deployments and includes a range of general feature improvements.
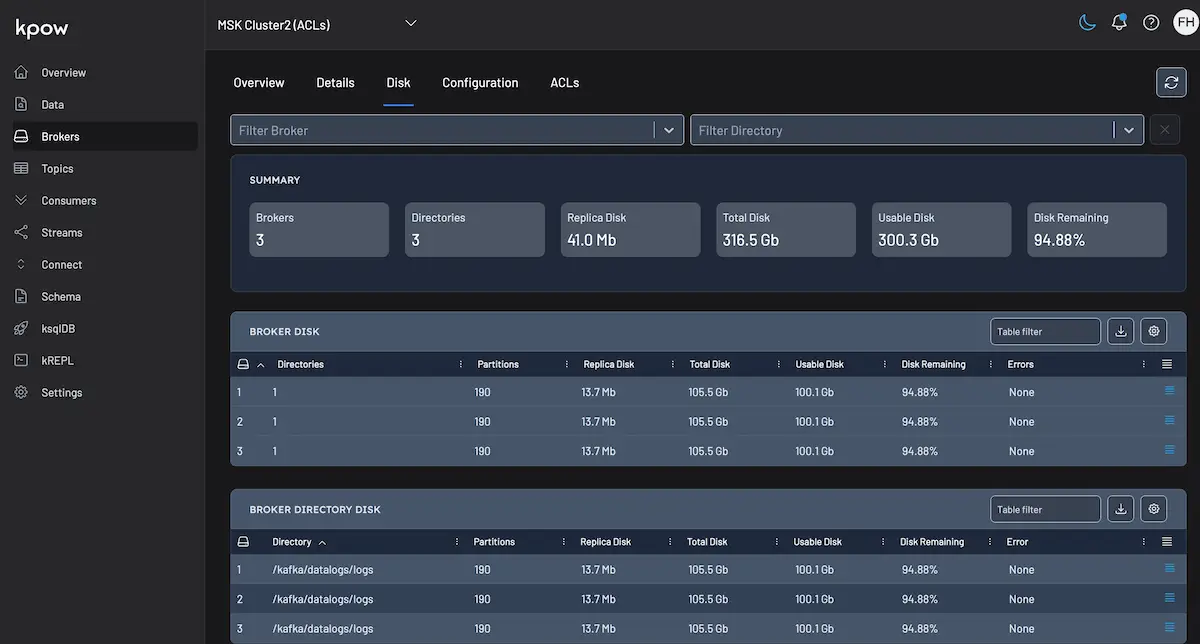
How-to
May 15, 2023
Delete Records in Kafka
This article provides a step-by-step guide on the various ways to delete records in Kafka.
Release
April 18, 2023
Release 91.3: Schema Configurability
Kpow v91.3 is a minor release that introduces new Schema and Connect features and resolves a number of small issues.
Events & Webinars
Stay plugged in with the Factor House team and our community.

Event
18 February 2026
Sydney Workshop: Building Resilient Event-Driven Systems with Kafka and Flink
We're teaming up with NetApp Instaclustr and Ververica to run this intensive half-day workshop where you'll design, build, and operate a complete real-time operational system from the ground up.

Event
19 February 2026
Melbourne Workshop: Building Resilient Event-Driven Systems with Kafka and Flink
We're teaming up with NetApp Instaclustr and Ververica to run this intensive half-day workshop where you'll design, build, and operate a complete real-time operational system from the ground up.
Join the Factor Community
We’re building more than products, we’re building a community. Whether you're getting started or pushing the limits of what's possible with Kafka and Flink, we invite you to connect, share, and learn with others.


