
Improvements to Data Inspect in Kpow 94.3
.webp)
Table of contents


Overview
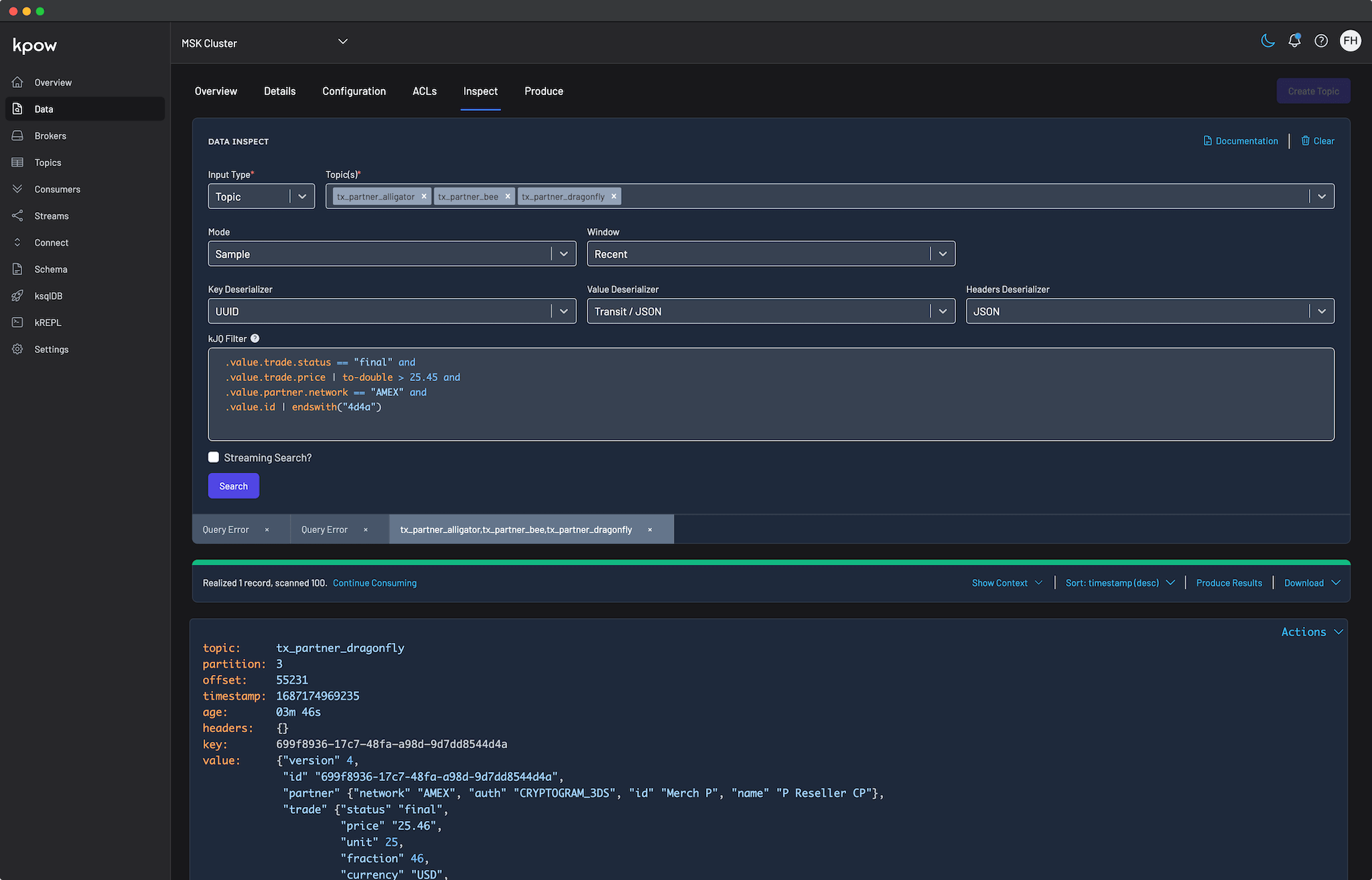
Kpow's Data Inspect feature has always been a cornerstone for developers working with Apache Kafka, offering a powerful way to query and understand topic data, as introduced in our earlier guide on how to query a Kafka topic.
The 94.3 release dramatically enhances this experience by introducing a suite of intelligent and user-friendly upgrades. This release focuses on making data inspection more accessible for all users while adding even more power for advanced use cases. The key highlights include AI-powered message filtering, which allows you to query Kafka using plain English; automatic deserialization, which removes the guesswork when dealing with unknown data formats; and significant enhancements to the kJQ language itself, providing more flexible and powerful filtering capabilities.
About Factor House
Factor House is a leader in real-time data tooling, empowering engineers with innovative solutions for Apache Kafka® and Apache Flink®.
Our flagship product, Kpow for Apache Kafka, is the market-leading enterprise solution for Kafka management and monitoring.
Start your free 30-day trial or explore our live multi-cluster demo environment to see Kpow in action.
AI-Powered Message Filtering
Kpow now supports the integration of external AI models to enhance its capabilities, most notably through its "bring your own" (BYO) AI model functionality. This allows you to connect Kpow with various AI providers to power features within the platform.
AI Model Configuration
You have the flexibility to configure one or more AI model providers. Within your Kpow user preferences, you can then set a default model for all AI-assisted tasks. Configuration is managed through environment variables and is supported for the following providers:
If you need support for a different AI provider, you can contact the Factor House support team.
Enhanced AI Features
The primary AI-driven feature is the kJQ filter generation. This powerful tool enables you to query Kafka topics using natural language. Instead of writing complex kJQ expressions, you can simply describe the data you're looking for in plain English.
Here's how it works:
- Natural Language Processing: The system converts your conversational prompts (e.g., "show me all orders over $100 from the last hour") into precise kJQ filter expressions.
- Schema-Awareness: To improve accuracy, the AI can optionally use the schemas of your Kafka topics to understand field names, data types, and the overall structure of your data.
- Built-in Validation: Every filter generated by the AI is automatically checked against Kpow's kJQ engine to ensure it is syntactically correct before you run it.
This feature is accessible from the Data Inspect view for any topic. After the AI generates a filter, you have the option to execute it immediately, modify it for more specific needs, or save it for later use. For best results, it is recommended to provide specific and actionable descriptions in your natural language queries.
It is important to be mindful that AI-generated filters are probabilistic and may not always be perfect. Additionally, when using cloud-based AI providers, your data will be processed by them, so for sensitive information, using local models via Ollama or enterprise-grade AI services with strong privacy guarantees is recommended.
For more details, see the AI Models documentation.

Automatic Deserialization
Kpow simplifies data inspection with its "Auto SerDes" feature. In the Data Inspect view, you can select "Auto" as the deserializer, and Kpow will analyze the raw data to determine its format (like JSON, Avro, etc.) and decode it for you. This is especially useful in several scenarios, including:
- When you are exploring unfamiliar topics for the first time.
- While working with topics that may contain mixed or inconsistent data formats.
- When debugging serialization problems across different environments.
- For onboarding new team members who need to get up to speed on topic data quickly.
To make these findings permanent, you can enable the Topic SerDes Observation job by setting INFER_TOPIC_SERDES=true. When active, this job saves the automatically detected deserializer settings and any associated schema IDs, making them visible and persistent in the Kpow UI for future reference.

kJQ Language Enhancements
In response to our customers' evolving filtering needs, we've significantly improved the kJQ language to make Kafka record filtering more powerful and flexible. Check out the updated kJQ filters documentation for full details.
Below are some highlights of the improvements:
Chained alternatives
Selects the first non-null email address and checks if it ends with ".com":
.value.primary_email // .value.secondary_email // .value.contact_email | endswith(".com")String/Array slices
Matches where the first 3 characters of transaction_id equal TXN:
.value.transaction_id[0:3] == "TXN"For example, { "transaction_id": "TXN12345" } matches, while { "transaction_id": "ORD12345" } does not
UUID type support
kJQ supports UUID types out of the box, including the UUID deserializer, AVRO + logical types, or Transit / JSON and EDN deserializers that have richer data types.
To compare against literal UUID strings, prefix them with #uuid to coerce into a UUID:
.key == #uuid "fc1ba6a8-6d77-46a0-b9cf-277b6d355fa6"
Conclusion
The 94.3 release marks a significant leap forward for data exploration in Kpow. By integrating AI for natural language queries, automating the complexities of deserialization, and enriching the kJQ language with advanced functions, Kpow now caters to an even broader range of users. These updates streamline workflows for everyone, from new team members who can now inspect topics without prior knowledge of data formats, to seasoned engineers who can craft more sophisticated and precise queries than ever before. This release reaffirms our commitment to simplifying the complexities of Apache Kafka and empowering teams to unlock the full potential of their data with ease and efficiency.