.svg)
Das Engineering-Toolkit
für Echtzeitdaten
Verwalten Sie Apache Kafka® und Apache Flink® über eine einzige Benutzeroberfläche und API. Durchsuchen Sie Zehntausende von Nachrichten pro Sekunde und setzen Sie Governance-Richtlinien in jedem Cluster durch.
Von führenden Unternehmen der Softwareentwicklung geschätzt
%20(1).svg)
.png)





.png)
.png)

.png)
.png)
.png)
Entdecken Sie unsere Produkte
Statten Sie Ihre Ingenieure mit den Werkzeugen aus, die sie benötigen, um Echtzeitsysteme sicher zu entwickeln.

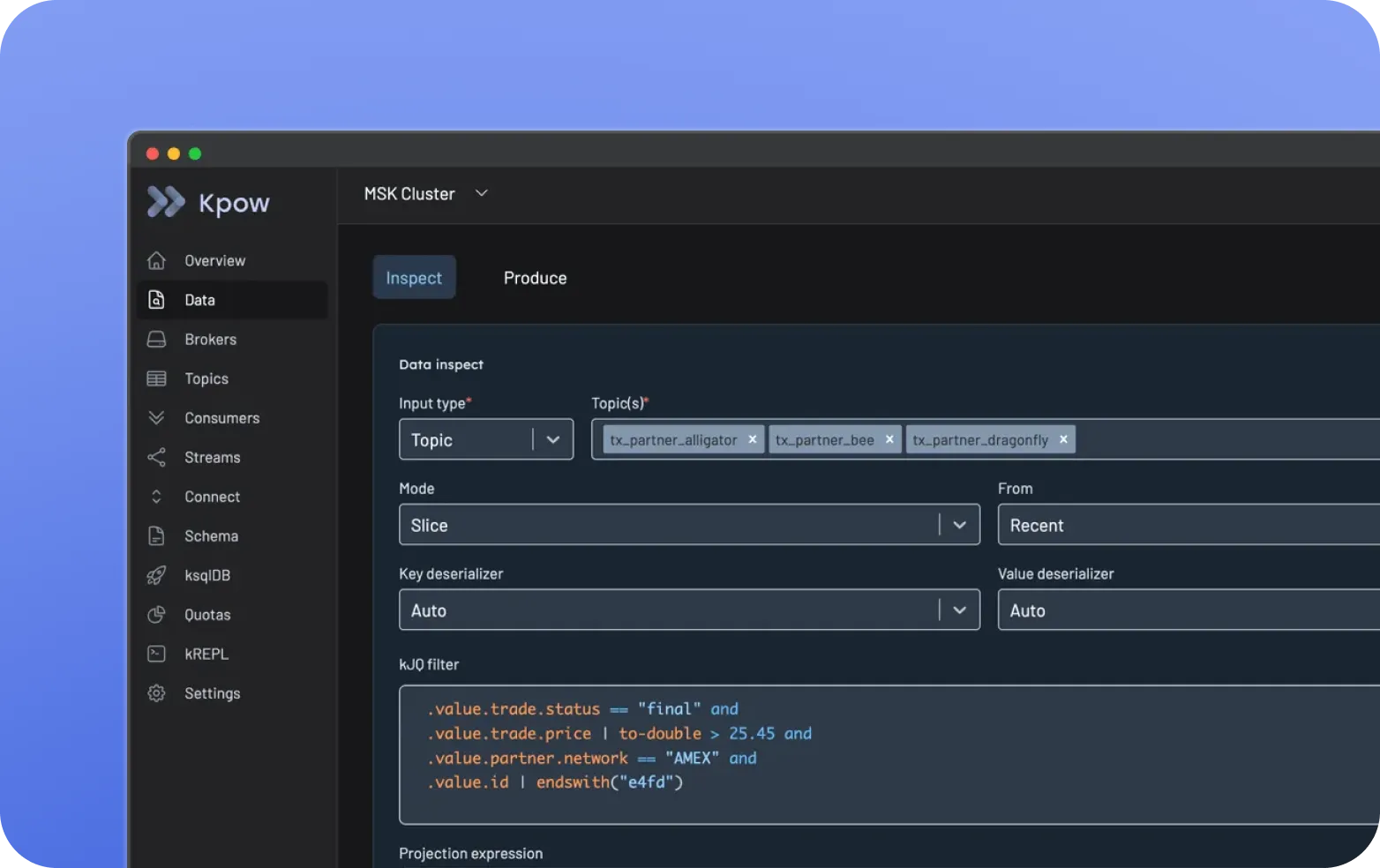

kJQ-Suche über Hunderte von Themen in Sekundenschnelle. Filtern Sie nach Schlüssel, Header oder Nachrichteninhalt mit JQ-ähnlicher Syntax. Regex-Themenabgleich, Suche über mehrere Topics, Streaming-Suche für Live-Debugging. Keine Wegwerf-Konsumenten.

Verwalten Sie Topics, ACLs, Consumer-Gruppen, Schemata und Konnektoren an einem Ort. Erstellen, prüfen, bearbeiten, löschen. Offsets zurücksetzen, „Poison Pills“ überspringen, Partitionen neu zuweisen, Schema-Versionen vergleichen. Vollständiger Lebenszyklus, vollständiger Audit-Protokoll.

Überwachen Sie Consumer-Verzögerungen nach Partition, Host und Broker. Echtzeit-Dashboards zeigen unterreplizierte Partitionen, blockierte Consumer und Durchsatzengpässe an. Prometheus-Endpunkte speisen Ihren bestehenden Observability-Stack.
kJQ-Suche über Hunderte von Themen in Sekundenschnelle
Verwalten Sie Topics, ACLs, Consumer-Gruppen, Schemata und Konnektoren an einem Ort
Überwachen Sie Consumer-Verzögerungen nach Partition, Host und Broker



Navigieren Sie durch Ausführungsgraphen, überprüfen Sie Knoten und verfolgen Sie den Datenfluss. Sehen Sie genau, wie Ihre Jobs strukturiert sind und wo die Verarbeitungszeit verbraucht wird.

Bereitstellung, Checkpointing, Savepointing und Abbruch über eine übersichtliche Benutzeroberfläche und API. Benutzerdefinierte Konfigurationen pro Job. Ordnungsgemäßes Herunterfahren. Kein Terminal erforderlich.

Analysieren Sie den Gegendruck und erkennen Sie Anomalien auf Knotenebene. Identifizieren Sie Pipeline-Engpässe mit ausreichender Detailgenauigkeit, um darauf reagieren zu können.
Navigieren Sie durch Ausführungsgraphen, überprüfen Sie Knoten und verfolgen Sie den Datenfluss
Bereitstellung, Checkpointing, Savepointing und Abbruch über eine übersichtliche Benutzeroberfläche und API
Analysieren Sie den Gegendruck und erkennen Sie Anomalien auf Knotenebene



Zentralisierte Verwaltung über Kafka- und Flink-Cluster hinweg. Weniger Dashboards, weniger CLIs, weniger Grafana-Registerkarten. Eine einzige Schnittstelle für Ihren Streaming-Stack.

Integrierte, fein abgestufte RBAC-Kontrolle, Audit-Protokollierung und Governance-Kontrollen. Mandantenfähigkeit, Datenmaskierung, Workflows für schrittweise Datenänderungen, SSO. Vom ersten Tag an produktionsbereit.

End-to-End-Datenherkunft von der Quelle bis zum Ziel. Verfolgen Sie Daten in Ihrem gesamten Echtzeit-Ökosystem. Sehen Sie, wo jede Nachricht gewesen ist.
Zentralisierte Verwaltung über Kafka- und Flink-Cluster hinweg
Integrierte, fein abgestufte RBAC-Kontrolle, Audit-Protokollierung und Governance-Kontrollen
End-to-End-Datenherkunft von der Quelle bis zum Ziel
Warum Factor House
Techniker an erster Stelle; Unternehmensniveau immer im Blick.

Entwickelt für technische Teams
Leistungsstarke, auf Entwickler ausgerichtete Tools für Kafka und Flink, die eine vollständige Überwachung und Verwaltung Ihres Streaming-Ökosystems ermöglichen.
Von Grund auf unternehmensfähig
Integrierte Funktionen für eine zuverlässige Skalierung im Unternehmen. Behalten Sie die Kontrolle über Sicherheit, Governance, Auditing und Zugriffskontrolle.
.png)
Wirklich flexibel, herstellerunabhängig
Unser selbstverwaltetes, flexibles Bereitstellungsmodell passt sich Ihrer Streaming-Strategie an und unterstützt Kafka- und Flink-Anbieter wie MSK, Confluent, Aiven, Ververica und viele mehr.
Bewährt im Produktionseinsatz
Vertrauen von Fortune-500-Unternehmen mit Tausenden von Ingenieuren und Millionen von Nachrichten pro Sekunde in ihren Kafka-Umgebungen.
Mehr Effizienz für Ihr Team
Unterstützt Ingenieure, DevOps- und Datenteams mit unübertroffener Leistung.
50k
50k
50k
4M+
50k
4M+
2x
50k
2x
Governance und compliance
Entwickelt für Umgebungen, in denen Governance, Sicherheit und nachprüfbare Maßnahmen unverzichtbar sind.






Factor House lässt sich sofort mit Okta, OpenID, LDAP, SAML und Keycloak integrieren. HTTPS, Datenmaskierung, Protokollierung von Benutzeraktionen und Prometheus-Endpunkte sind Standard. Rollenbasierte Zugriffskontrollen unterstützen temporär erweiterte Berechtigungen und mehrstufige Mutations-Workflows, die eine Genehmigung für destruktive Vorgänge erfordern. Die Barrierefreiheit entspricht vollständig den WCAG 2.1 AA-Standards.
Von Ingenieuren geliebt.
Von Unternehmen vertraut.
Engineering-Teams vertrauen auf Factor House für zuverlässige, skalierbare und entwicklerfreundliche Lösungen.



„Ich bin dankbar für das Einfühlungsvermögen und die Leidenschaft, die das Team von Factor House bei der Zusammenarbeit mit Airwallex gezeigt hat, um unsere Probleme besser zu verstehen und so die Weiterentwicklung dieses brillanten Produkts voranzutreiben.“
.png)
„Kpow ist nicht nur intuitiv und benutzerfreundlich, sondern spart uns auch Zeit, und unsere Entwickler arbeiten gerne damit. Wenn es ein Problem mit unserem Kafka-System gibt, gibt es keine bessere Möglichkeit zur Fehlerverfolgung als mit Kpow. Wer Kafka kennt, sollte auch Kpow kennen.“
„Kpow hat die Art und Weise verbessert, wie wir Kafka dem Rest des IT-Teams und dem Unternehmen vermitteln. Es hat uns dabei geholfen, einzuschätzen, was wir in Zukunft möglicherweise tun müssen, und Probleme im Zusammenhang mit Entwicklungs- und Infrastrukturstandards zu identifizieren. Der Einsatz in unserem Ökosystem hat uns einen viel besseren Überblick über Kafka und darüber verschafft, wie unser gesamtes System zu jedem beliebigen Zeitpunkt funktioniert. Wenn ich etwas in unserem Cluster sehen möchte, kann ich jetzt zuerst zu Kpow gehen.“

„Kpow wurde von einem Team entwickelt, das eine Leidenschaft für Kafka hat, aber auch die Narben einiger schwieriger Implementierungen trägt. Es ist ein Tool von und für Ingenieure und bietet unserem Team den einfachsten, schnellsten und kostengünstigsten Weg, auf seine Daten zuzugreifen, und arbeitet nahtlos mit Amazon MSK zusammen. Es wird ein wichtiger Bestandteil unserer Infrastruktur sein, solange wir Kafka nutzen.“

Blog
Entdecken Sie praxisnahe Anleitungen, Produktupdates und technische Einblicke, um Kafka, Flink und Factor House optimal zu nutzen.

.png)
Release 96.1: Factor Platform, performance Improvements and new features in Kpow and Flex
Factor House release v96.1 brings significant new product features and performance enhancements to our Kafka and Flink tooling, and makes Factor Platform publicly available for early-access users.

Defense in depth: unifying RBAC and data policies for transparent governance
Balance Kafka velocity and compliance. Learn how Kpow uses RBAC and Data Policies for safe, self-service production debugging without manual tickets.

Apache Kafka 4.3.0: A guide for platform engineers
Kafka 4.3.0 is an operator-focused release with 25 KIPs covering broker cordoning, retention headroom metrics, share group tuning, and tiered storage correctness fixes. This article covers the changes with operational impact and what to do before you upgrade.
Probieren Sie es selbst aus
Stellen Sie innerhalb weniger Minuten eine Verbindung zu einem beliebigen Kafka-Cluster her. Stellen Sie die Lösung über Docker, Helm oder JAR bereit. 30 Tage lang uneingeschränkter Zugriff.