
How-to
Empowering engineers with everything they need to build, monitor, and scale real-time data pipelines with confidence.

.webp)
Set Up Kpow with Google Cloud Managed Service for Apache Kafka
Integrate Kpow with Google Cloud Managed Service for Apache Kafka (MSAK) in minutes. Gain unified visibility and control over your managed Kafka brokers and Schema Registry through our market-leading engineering console.
.webp)
Set Up Kpow with Amazon Managed Streaming for Apache Kafka
Integrate Kpow with Amazon Managed Streaming for Apache Kafka (MSK) in minutes. Gain unified visibility and control over your AWS brokers, MSK Connect, and Glue Schema Registry through our market-leading engineering toolkit.
.webp)
Manage Kafka Consumer Offsets with Kpow
Kpow version 94.2 enhances consumer group management capabilities, providing greater control and visibility into Kafka consumption. This article provides a step-by-step guide on how to manage consumer offsets in Kpow.
.webp)
Set Up Kpow with Confluent Cloud
Integrate Kpow with Confluent Cloud in minutes. Gain unified visibility and control over your managed Kafka brokers, Schema Registry, Managed Connect, and ksqlDB through our market-leading engineering toolkit.
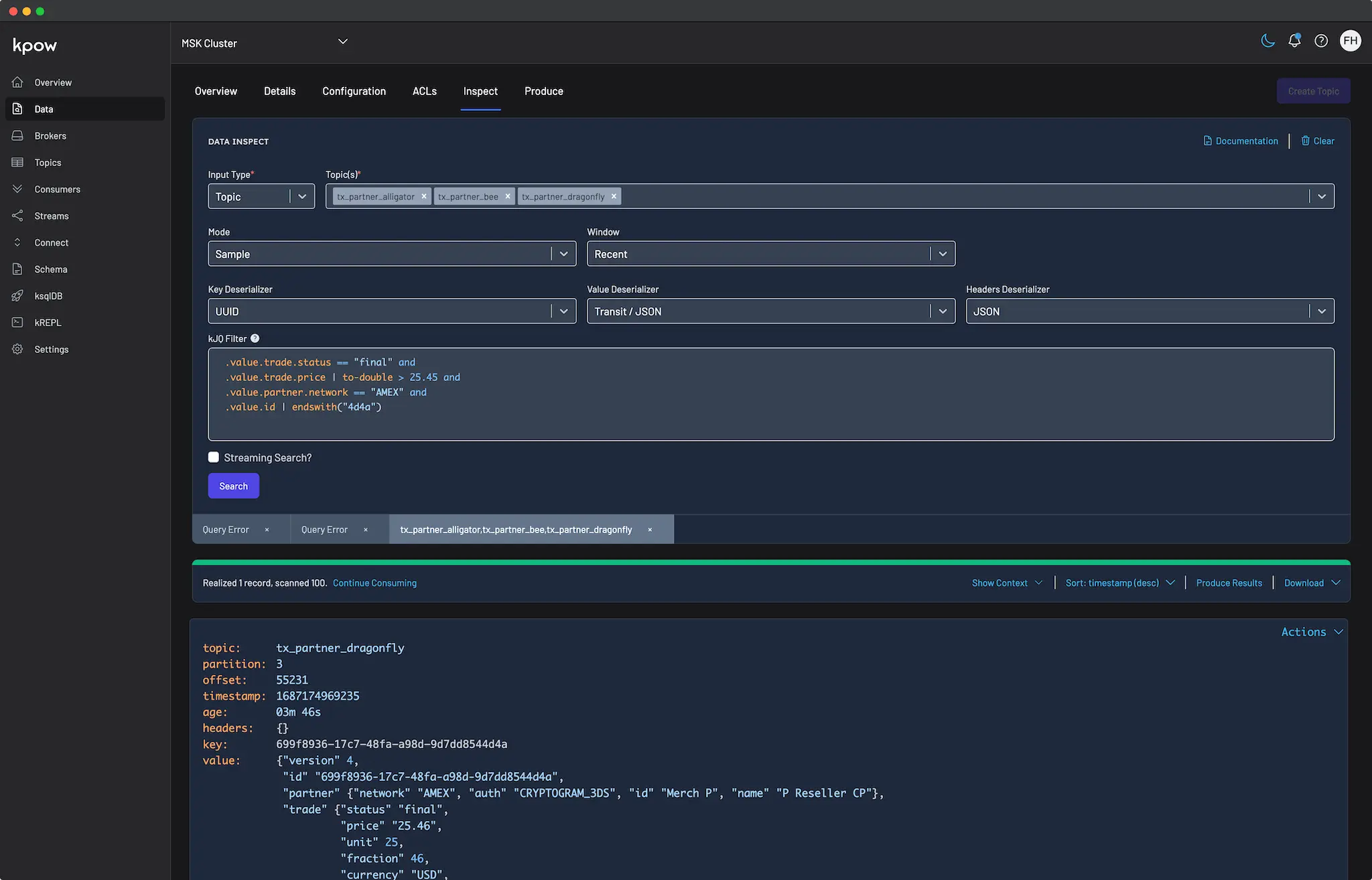
How to query a Kafka topic
Querying Kafka topics is a critical task for engineers working on data streaming applications, but it can often be a complex and time-consuming process. Enter Kpow's data inspect feature—designed to simplify and optimize Kafka topic queries, making it an essential tool for professionals working with Apache Kafka.
Delete Records in Kafka
This article provides a step-by-step guide on the various ways to delete records in Kafka.
Join the Factor Community
We’re building more than products, we’re building a community. Whether you're getting started or pushing the limits of what's possible with Kafka and Flink, we invite you to connect, share, and learn with others.


