
KIP-1150 Diskless Topics: Rethinking Storage and Cloud Costs in Kafka

Table of contents


Overview
Operating Apache Kafka in public clouds at massive scale has traditionally meant grappling with high infrastructure costs, specifically around block storage and inter-Availability Zone (AZ) network transfer. While the introduction of Tiered Storage (KIP-405) helped offload historical data, active replication still forces engineers to pay a premium for high-performance disks and network bandwidth.
Recently accepted as a consensus document, KIP-1150: Diskless Topics represents a major architectural pivot for the Apache Kafka community. By proposing native object storage for active segments, Diskless Topics aim to fundamentally change how data is stored and replicated. If successfully implemented, this architecture will bring true cloud-native scalability and cost-efficiency to Kafka.
Blending object storage semantics with real-time streaming requires a shift in operational thinking. In this article, we will explore what KIP-1150 proposes, the cloud infrastructure problems it targets, how it aligns with broader industry trends, and the new monitoring complexities teams will need to manage as the design becomes a reality.
About Factor House
Factor House is a leader in real-time data tooling, empowering engineers with innovative solutions for Apache Kafka® and Apache Flink®.
Our flagship product, Kpow for Apache Kafka, is the market-leading enterprise solution for Kafka management and monitoring.
Start your free 30-day trial or explore our live multi-cluster demo environment to see Kpow in action.
Key takeaways
- Reduction in cross-AZ costs: Diskless topics bypass standard broker-to-broker replication, significantly reducing network fees. However, this trades replication costs for object storage API and transfer fees.
- "Diskless" is like "Serverless": It does not mean zero disks. Brokers will still use disks for KRaft metadata, caching, and batch metadata, but user data is written through to highly durable object storage.
- Cost vs. Latency tradeoff: Operators will have the ability to choose between low-latency classic block-storage topics and highly cost-optimized diskless topics on a per-topic basis.
- New monitoring horizons: Abstracting storage away from local disks into remote object storage requires entirely new visibility strategies for caching, ingestion engines, and object store performance.
Background: Shift to Decoupled Architecture
To fully understand the necessity of KIP-1150, we must look at three converging forces reshaping the data landscape. The most immediate catalyst is the financial friction between traditional Kafka architecture and modern cloud economics. Beyond pure cost optimization, this evolution is in line with the broader industry shift toward separating compute from storage, alongside mounting market pressure from new object-storage-first streaming vendors. Together, these factors make Diskless Topics a critical step forward.
Traditional Architecture vs. Cloud Economics
Kafka was originally designed for commodity hardware. It relies on low-durability local block storage and direct broker-to-broker replication to ensure high availability and data safety. However, modern public clouds financially penalize this specific design. Major cloud providers like AWS and GCP charge heavily for cross-Availability Zone network traffic, often between $0.01 to $0.02 per GiB. Furthermore, provisioned block storage is considerably more expensive than object storage like Amazon S3 or Google Cloud Storage.
While the introduction of Tiered Storage (KIP-405) was a fantastic milestone, it only solved the cost problem for inactive, historical data. Active data still requires expensive local disk provisioning and incurs high replication network costs.
Industry Shift to Decoupling
This friction between legacy architecture and cloud pricing is not unique to event streaming. The broader data ecosystem solved this exact problem years ago by fundamentally decoupling compute resources from storage layers. Modern data warehouse solutions like Snowflake, Amazon Redshift, and Google BigQuery revolutionized cloud analytics by moving their ultimate source of truth to highly durable, low-cost object storage. This architectural shift proved that data platforms could achieve massive scale and cost efficiency without sacrificing reliability.
Market Pressure in Event Streaming
Naturally, this separation of compute and storage has now arrived in the real-time streaming space. Recognizing the financial burden of running traditional Kafka in the cloud, several alternative vendors capitalized on this architectural gap to build object-storage-first streaming engines. Platforms like AutoMQ and WarpStream built Kafka-compatible engines backed entirely by object storage. Similarly, StreamNative recently expanded beyond Apache Pulsar to offer a Kafka-compatible engine that also leverages a decoupled storage architecture.
KIP-1150 as Kafka's Native Response
Rather than allowing alternative platforms to dictate the future of cloud-native streaming, the Apache Kafka community accepted KIP-1150 as a roadmap to incorporate decoupled innovation natively. By planning to utilize object storage for active segments, KIP-1150 addresses these industry forces simultaneously. It tackles the financial friction of cloud block storage, aligns Kafka with the principle of separating compute from storage, and provides a robust answer to emerging competitors.
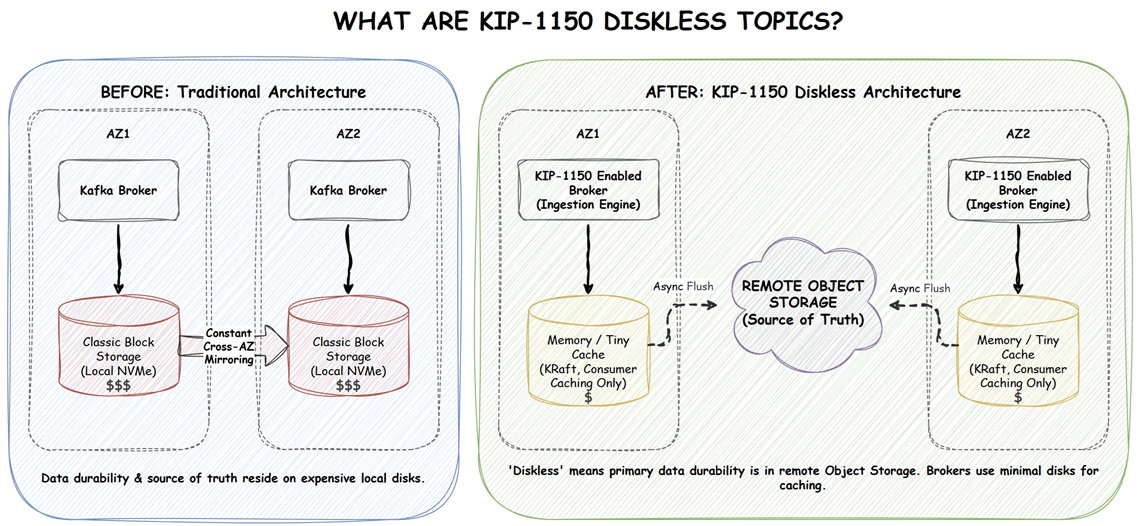
What are KIP-1150 Diskless Topics?
KIP-1150 introduces a blueprint for a new type of topic equipped with a distinct ingestion engine. Instead of relying purely on local block storage for durability and replication, this proposed engine writes data through directly to object storage.
It is important to clarify the terminology. "Diskless" does not mean broker disks vanish entirely. Disks are still utilized for KRaft metadata, caching consumer data, and short-term staging. However, the primary source of truth and data durability completely shifts from the local disk to the remote object store.
What does KIP-1150 solve?
KIP-1150 directly targets the most significant infrastructure pain points that platform engineers face today.
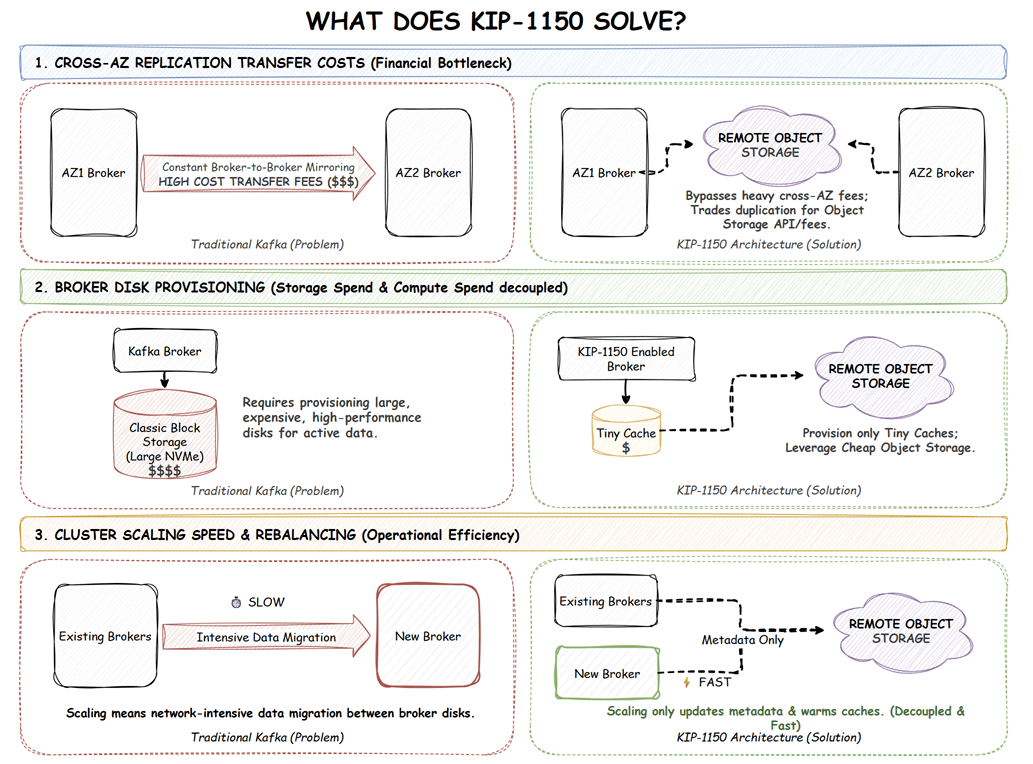
Drastically reducing replication transfer costs
By relying on object storage for durability, brokers will no longer need to constantly mirror gigabytes of data across availability zones to maintain replication factors. This largely bypasses the expensive cross-AZ network transfer bills that plague large-scale cloud deployments. It is worth noting that costs are not entirely eliminated. Operators trade heavy broker-to-broker network fees for object store API and data transfer costs, which are generally much cheaper but still require architectural consideration.
Infrastructure optimization
Operators can provision brokers with extremely small, highly performant disks (or even memory-backed storage) merely for caching. Relying on cheap object storage for actual data retention drastically reduces monthly block storage spend.
Decoupled scaling
In traditional Kafka, scaling out a cluster means physically moving large volumes of data between broker disks, a process that is notoriously slow and network-intensive. With Diskless Topics, the canonical data safely resides in object storage. Brokers can scale up and rebalance significantly faster because they only need to update metadata and warm up their caches, completely bypassing heavy data migration.
How will Diskless Topics work?
KIP-1150 is a consensus and architectural document. Its primary goal is to align the community on the need and the high-level concept. The actual codebase implementation is deliberately split into proposed follow-up designs, including KIP-1163 (Diskless Core) and KIP-1164 (Diskless Coordinator).
At an architectural level, Diskless Topics are envisioned to operate via an ingestion engine running parallel to the classic topic engine. Data will remain accessible to consumers both from the ingestion engine cache and directly from tiered storage.
Anticipated Write Path
To maintain reasonable performance while writing to high-latency object storage, the ingestion engine cannot simply block producer requests waiting for S3 HTTP responses. Instead, the architecture will heavily rely on local staging. When a producer sends data, the ingestion engine will likely use local memory or a highly optimized disk cache to stage the incoming records. Depending on the configured durability guarantees, the broker might acknowledge the producer immediately after local staging, or wait for an asynchronous background process to flush these batches to the remote object store. Balancing fast producer acknowledgments with the strict durability guarantees of object storage is where the real engineering complexity lies.
What complexities does KIP-1150 introduce?
While the financial and operational benefits of Diskless Topics are highly appealing, they introduce new tradeoffs and visibility challenges.
Ambitious backward compatibility
The KIP states a goal of being entirely backwards compatible with existing Kafka APIs, including strict ordering guarantees, idempotency, and consumer group semantics. Achieving these semantics over a remote object-storage hot path is a massive, non-trivial engineering challenge. Ensuring consistency when the primary storage layer operates asynchronously over HTTP will require careful design and likely extensive real-world testing once implemented.
Latency Trade-offs
Writing through to an object store naturally introduces higher produce latency compared to writing directly to a local NVMe drive. Applications that require strict, ultra-low microsecond latency will likely need to stick to classic block-storage topics. Platform teams will need to carefully categorize workloads to determine which topics should be diskless and which must remain classic.
Obscured Storage Visibility
Troubleshooting local disk bottlenecks is a well-understood science. However, troubleshooting object storage API rate limits, write-through cache misses, and ingestion engine latency introduces a totally new paradigm. Traditional monitoring strategies relying on simple JMX disk metrics will no longer show the complete picture.
Factor House is actively preparing for these new topologies. As storage paradigms shift from local disks to remote object stores, we recognize that traditional monitoring tools will leave operations teams with significant blind spots. Factor House is actively tracking the development of KIP-1150 and its sub-KIPs to ensure Kpow will provide seamless, purpose-built observability into remote storage latencies, cache hit rates, and overall diskless topic performance.
Looking Ahead: Future of Diskless Kafka
KIP-1150 serves as the foundational layer for a highly anticipated roadmap of future Kafka enhancements. Once the core diskless functionality is implemented, it unlocks several exciting possibilities:
- Lakehouse (e.g., Apache Iceberg) Integration: By writing data natively to object storage, Kafka paves the way for massively parallel analytical processing on at-rest topic data using open table formats.
- Topic Type Changing: Future updates aim to allow operators to dynamically convert topics back and forth between classic and diskless configurations as business needs evolve.
- Heterogeneous Clusters: Because data will live securely in object storage, brokers in a cluster will no longer need to be identical clones of each other. Operators could provision distinct types of hardware for specific jobs, such as using high-CPU machines dedicated solely to ingesting incoming data, or high-memory machines exclusively for serving consumers, to maximize resource efficiency.
Our take at Factor House
KIP-1150 represents a critical proposed evolution for Apache Kafka. By embracing the separation of compute and storage, it lays the groundwork for Kafka to remain a highly competitive and cost-effective streaming engine regardless of shifting cloud architecture trends. If successful, it offers a massive win for organizations looking to drastically reduce their cloud infrastructure costs while achieving easier, faster cluster scalability.
We believe that operational tooling must evolve at the same pace as the infrastructure it monitors. The transition from block storage to object storage introduces significant complexities. We are incredibly excited about this evolving era of cloud-native Kafka, and we are committed to updating Kpow right alongside Kafka's core architecture to ensure you maintain total visibility and control.
Next steps
Explore Kpow in your own environment with a free 30-day trial.
If you need assistance managing your Kafka environment or preparing for upcoming architecture shifts, reach out to our engineering support team at support@factorhouse.io.