
Kafka Data Management with Kpow: Unlocking Engineering Productivity

Table of contents


Overview
Event-driven architectures promise massive scalability and decoupled agility. In reality, the day-to-day experience of building and maintaining these systems often reveals underlying friction. While infrastructure teams have mastered the art of keeping brokers online, application teams frequently face obstacles when trying to access, debug, or correct the actual payloads flowing through their topics.
This disconnect creates a drag on engineering velocity. When a transaction fails in production, a downstream database crashes, or a poison pill stalls a consumer, developers need instant access to structured data. Instead, teams are slowed down by manual data configuration, forced to build custom tools to find specific events in high-volume streams, or blocked by restrictive permissions that prevent them from accessing the data they need.
Organizations require a structural shift away from fragmented command-line tasks toward a frictionless, self-service developer experience. This article outlines a comprehensive strategy to identify and mitigate the four critical gaps causing friction in enterprise Kafka data management, demonstrating how Kpow serves as the unified engine to unlock engineering productivity.
To see how these concepts translate into practical workflows, follow along with our upcoming four-part technical guide:
- Part 1: Foundational Kafka Data Inspection: Shaping Payloads and Optimizing Visibility
- Part 2: Accelerating Incident Response: Advanced Filters, Streaming Search, and AI-Powered Queries
- Part 3: Triage, Repair, and Replay: Integrated Kafka Remediation Workflows
- Part 4: Defense in Depth: Unifying RBAC and Data Policies for Transparent Governance
About Factor House
Factor House is a leader in real-time data tooling, empowering engineers with innovative solutions for Apache Kafka® and Apache Flink®.
Our flagship product, Kpow for Apache Kafka, is the market-leading enterprise solution for Kafka management and monitoring.
Start your free 30-day trial or explore our live multi-cluster demo environment to see Kpow in action.
Four Critical Gaps in Enterprise Data Management
Unlocking developer productivity requires identifying and mitigating the operational bottlenecks that occur when teams interact with Kafka data.
Visibility Gap: Opacity of High-Volume Data
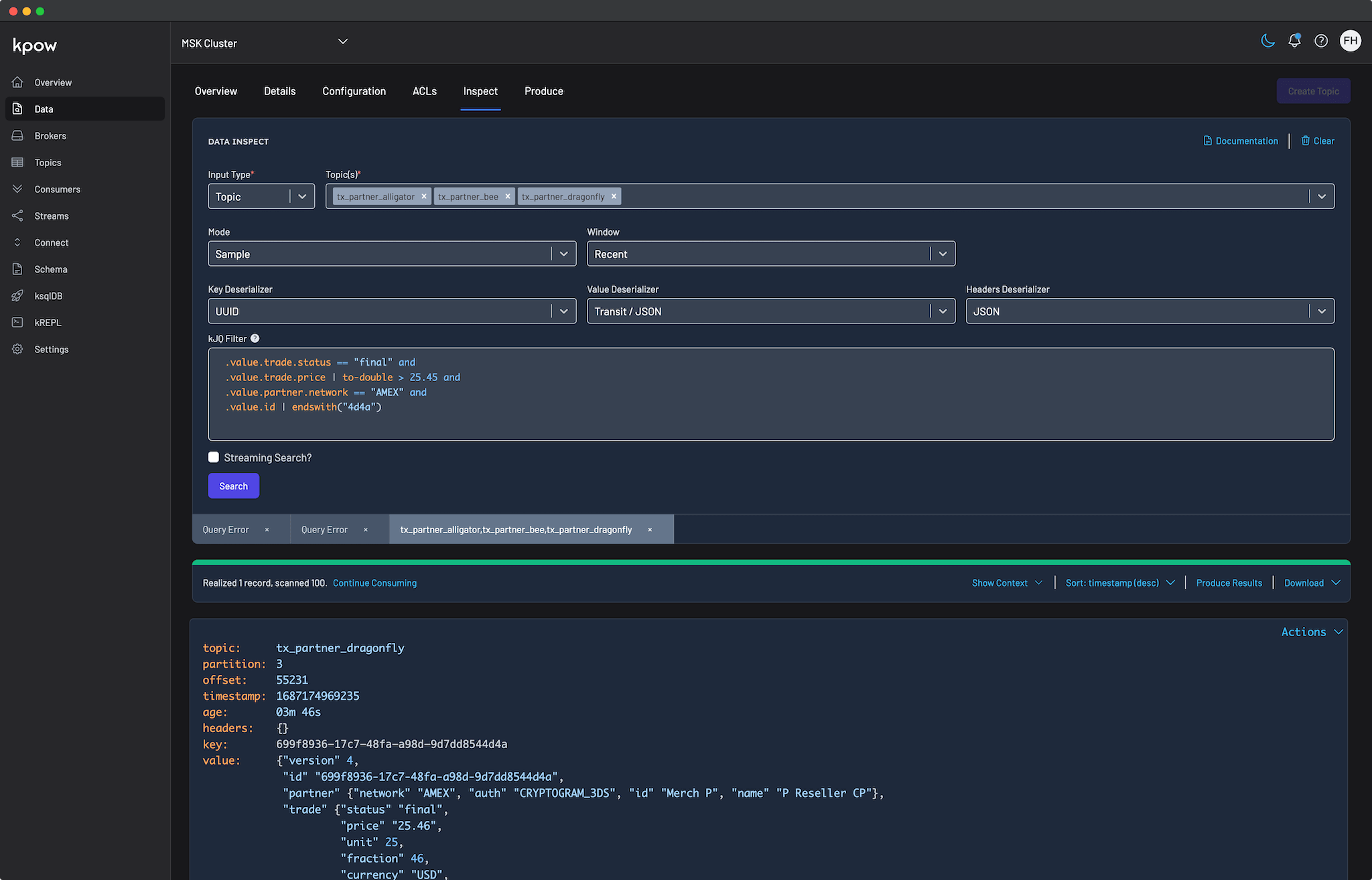
Application teams often lack immediate visibility into topic data. During an investigation, determining partition-level scanning progress can be difficult, and large, deeply nested JSON or Avro payloads are frequently hard to parse. Engineers often rely on standard CLI consumers, which require manual reconfiguration of schema registry properties for different topics and typically output unformatted payloads. Furthermore, configuring performant, secure inspection tools in containerized environments presents an ongoing challenge for platform administrators.
Velocity Gap: Friction of Incident Response
Finding a specific event in a high-volume topic often requires sifting through millions of messages. Isolating a single failure buried within deeply nested JSON payloads requires developers to write complex search queries or command-line filters. Figuring out the exact code to filter this data takes time, which directly delays incident response. Standard workflows force teams to write custom parsing scripts, manually step through offsets, or rely on shared text files of old query commands. During a high-pressure outage, this trial-and-error approach to finding data adds severe friction to the resolution process.
Remediation Gap: Fragmented Pipeline Repair
Fixing data pipelines extends beyond identifying a schema mismatch that stalls a consumer. Teams must frequently triage Dead Letter Queues (DLQs) for validation errors, or rewind consumer offsets when a downstream database crashes. However, extracting this data, unblocking the consumer, and repairing the pipeline involve separate, fragmented workflows. Developers may write custom scripts to find errors or bulk-publish missing headers, while simultaneously coordinating with platform engineers to manually reset consumer offsets via CLI commands. This fragmentation introduces delays in restoring data pipelines and extracting clean data for reporting.
Compliance Gap: Risk of Exposed Payloads
Organizations face strict regulatory constraints regarding Personally Identifiable Information (PII). Providing application teams with unrestricted access to production topics introduces compliance risks. To mitigate this, platform administrators often restrict access, requiring developers to use ticketing systems to request data. Platform engineers must then manually extract and sanitize logs before returning the data, creating an operational bottleneck that slows down development and debugging.
Kpow Solution: Unifying Data Workflows
Overcoming these gaps requires a unified platform that provides deep inspection capabilities, efficient search, integrated remediation, and robust data governance. Kpow addresses these requirements across four key operational dimensions.
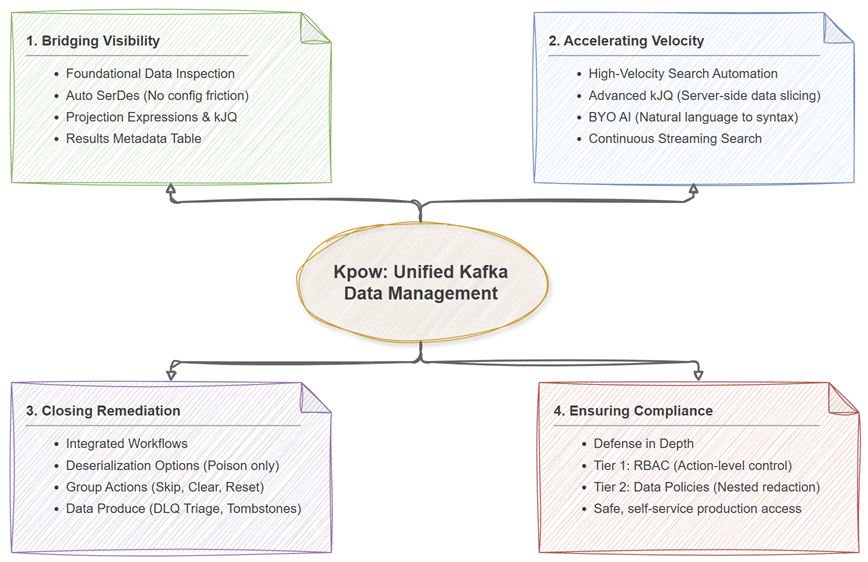
Bridging Visibility with Foundational Data Inspection
Kpow brings structured clarity to cluster data through its Data Inspect capabilities. By leveraging Auto SerDes, Kpow infers schemas automatically, eliminating the manual configuration overhead associated with traditional consumers. Users can apply kJQ filters and Projection Expressions to extract specific nested fields, simplifying data analysis. Additionally, the Results Metadata Table provides transparent, partition-level query context and offset exhaustion metrics. Platform teams can also tune worker configuration variables to ensure stable, performant access across the enterprise.
Accelerating Velocity with AI and Streaming Search
To accelerate incident response, Kpow equips teams with powerful tools for high-velocity data analysis. Users can leverage advanced kJQ filtering for rapid, server-side data slicing, for example by evaluating date mathematics or extracting data from embedded JSON arrays. To make this advanced syntax instantly accessible and eliminate the traditional learning curve, Kpow integrates Bring Your Own AI (BYO AI) capabilities supporting AWS Bedrock, OpenAI, Anthropic, and Ollama. Operators can simply use natural language prompts to automatically generate schema-aware, syntactically validated kJQ filters. Furthermore, Streaming Search provides continuous, automatic query progression until result limits are reached or topics are completely exhausted.
Closing Remediation with Integrated Workflows
Kpow consolidates the remediation lifecycle for a wide range of pipeline failures. For serialization errors, users can leverage one of the deserialization options (such as Poison only) to easily isolate malformed data. If a downstream database fails, Kpow incorporates consumer group actions, allowing operators to explicitly skip, clear, or reset offsets, for example, by rewinding to a specific timestamp to replay historical data. For DLQ triage, native UI routing allows teams to send queried results directly to Data Produce. This enables operators to correct validation errors, append missing headers, and seamlessly re-inject messages, or generate safe tombstone records for targeted deletion. Throughout these workflows, Kpow supports data downloads in standard business formats for offline auditing as well.
Ensuring Compliance with Defense in Depth
Kpow helps reduce reliance on manual ticketing through transparent data governance, framing security as a two-tiered model using a shared YAML resource taxonomy. In the first tier, granular Role Based Access Control (RBAC) allows administrators to grant TOPIC_INSPECT permissions while explicitly denying or staging sensitive TOPIC_PRODUCE actions. In the second tier, Data Policies layer onto inspection rules to apply nested redaction (such as ShowLast4 on a credit card field). This preventative control enables self-service debugging in production while maintaining PII protection.
Achieving Engineering Productivity
Improving engineering productivity requires reducing the operational friction between developers and their streaming data. It demands a strategy that provides clear visibility, accelerates search workflows, integrates data and pipeline repair, and transparently secures both administrative actions and sensitive payloads. By adopting a unified workflow for Kafka data management, organizations can minimize administrative bottlenecks, enable self-service operations, and better leverage their streaming architecture.
Equipping teams with the right tools makes Kafka a more accessible and efficient data backbone. By streamlining data discovery, remediation, and compliance workflows, Kpow enables engineering organizations to focus their efforts on building resilient, real-time applications.