Overview
While Kafka provides massive throughput, extracting actionable signal from high-volume streams presents a significant operational challenge that can easily disrupt enterprise engineering velocity. Among these challenges, the most significant is the “Visibility Gap”. This inherent opacity of streaming data leaves application teams struggling to parse complex payloads and locate specific events during critical incidents.
Turning raw Kafka payloads into readable, searchable data is the first step toward faster operational response. This article explores the root causes of data opacity and demonstrates how Kpow provides a structured, UI-driven approach to foundational data inspection to close the “Visibility Gap”.
This is Part 1 of the Kafka Data Management with Kpow: Unlocking Engineering Productivity series. You can read the full strategy in the main series article and access the associated posts as they become available:
- Part 1: Foundational Kafka Data Inspection: Shaping Payloads and Optimizing Visibility (This article)
- Part 2: Accelerating Incident Response: Advanced Filters, Streaming Search, and AI-Powered Queries
- Part 3: Triage, Repair, and Replay: Integrated Kafka Remediation Workflows
- Part 4: Defense in Depth: Unifying RBAC and Data Policies for Transparent Governance
About Factor House
Factor House is a leader in real-time data tooling, empowering engineers with innovative solutions for Apache Kafka® and Apache Flink®.
Our flagship product, Kpow for Apache Kafka, is the market-leading enterprise solution for Kafka management and monitoring.
Start your free 30-day trial or explore our live multi-cluster demo environment to see Kpow in action.
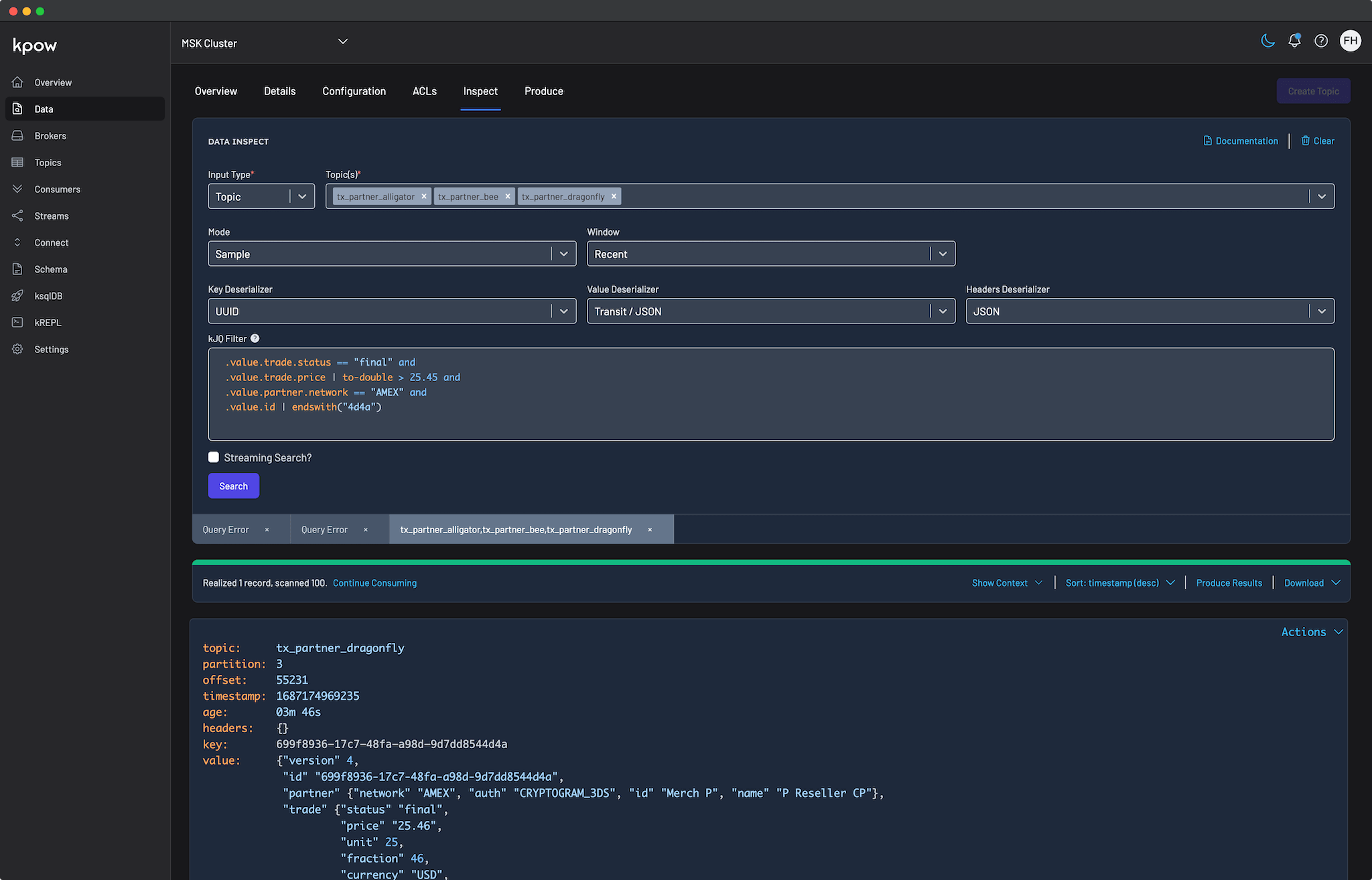
Problem: Opacity in High-Volume Topics
Application teams often lack direct insight into their topic data. In a typical microservices environment, a single topic might process thousands of messages per second containing deeply nested JSON or Avro structures. During a routine investigation, developers face overwhelming visual noise when trying to read these massive payloads.
Furthermore, teams suffer from a lack of search context regarding partition-level scanning progress. When searching across millions of messages for a specific correlation ID, developers have no idea how far along a partition scan has progressed or if they have completely exhausted the available offsets. This lack of feedback turns event discovery into an opaque, uncertain process.
Limitations of Disconnected CLI Tools
To solve these challenges, engineers often rely on standard open-source consumer scripts. This approach immediately introduces significant configuration overhead. Because enterprise environments utilize various data formats, engineers are forced to manually supply complex schema registry flags and deserialization properties for every single query they execute.
Once the consumer is finally configured, the output creates another bottleneck. Terminal screens are flooded with raw, unparsed payloads. Without the ability to shape or filter the output effectively, it becomes nearly impossible to quickly identify the relevant fields required for an investigation.
Streamlined Inspection with Kpow
Kpow eliminates the friction of CLI-based investigations by providing a powerful data inspect engine for querying and filtering topic data. This enables application teams to query topics directly from the browser while shaping the data for maximum readability.
Instant Schema Inference with Auto SerDes
To remove manual configuration overhead, Kpow features an intelligent Auto SerDes option. Instead of manually specifying deserializers and registry URLs, application teams simply select a topic. Kpow automatically analyzes the stream, infers the correct format (such as Avro, Protobuf, or JSON), and deserializes the payload correctly. This capability provides immediate data inspection without requiring prior knowledge of topic serialization formats.
Filtering and Shaping Payloads with kJQ and Projection Expressions
Once data is accessible, finding the right events and improving payload readability become critical. Kpow addresses the search challenge by introducing kJQ filters, a fast, JQ-like filtering language built specifically for Kafka topics. Designed for high performance, kJQ can easily scan tens of thousands of messages per second, allowing developers to rapidly search and isolate specific events directly on the server.
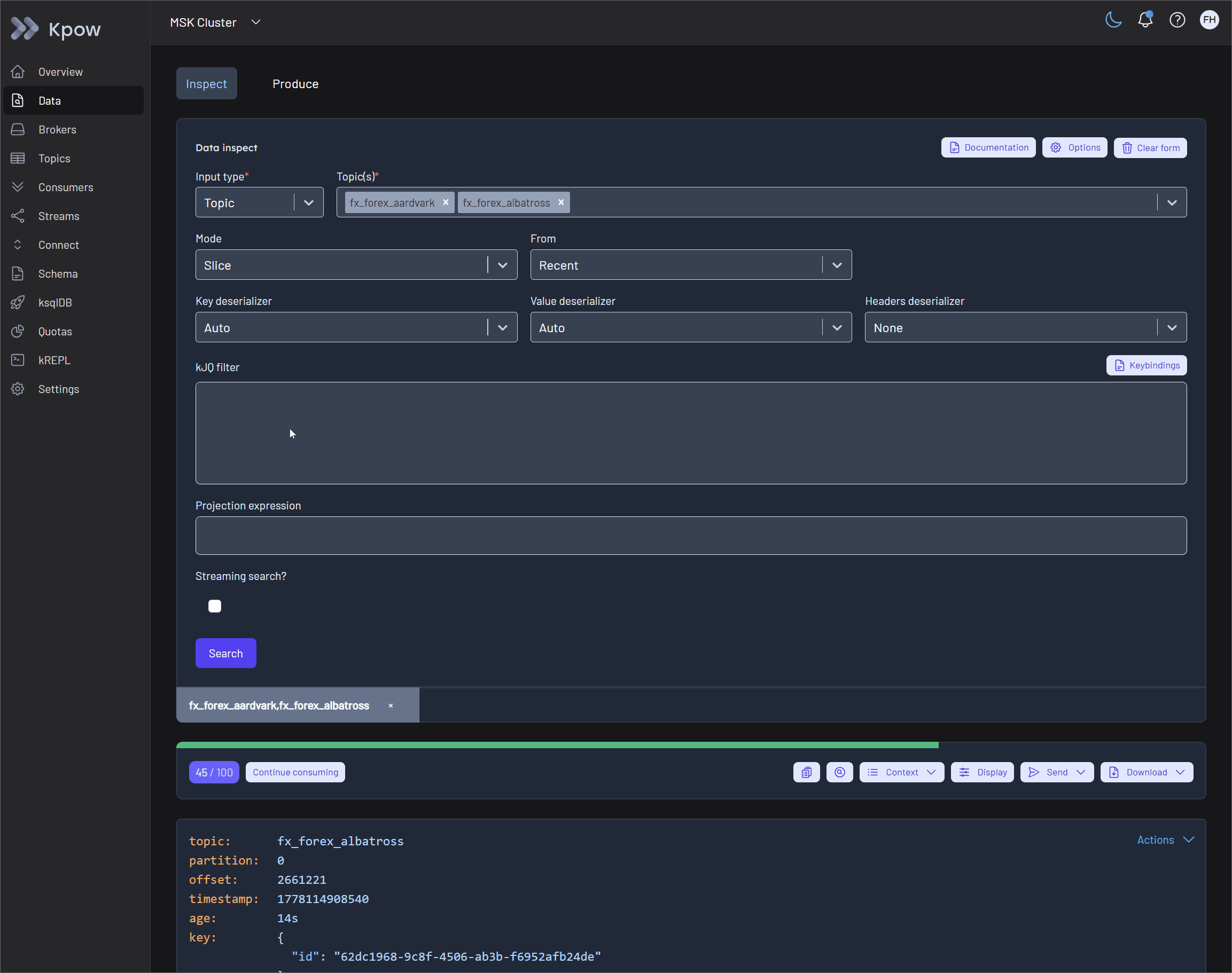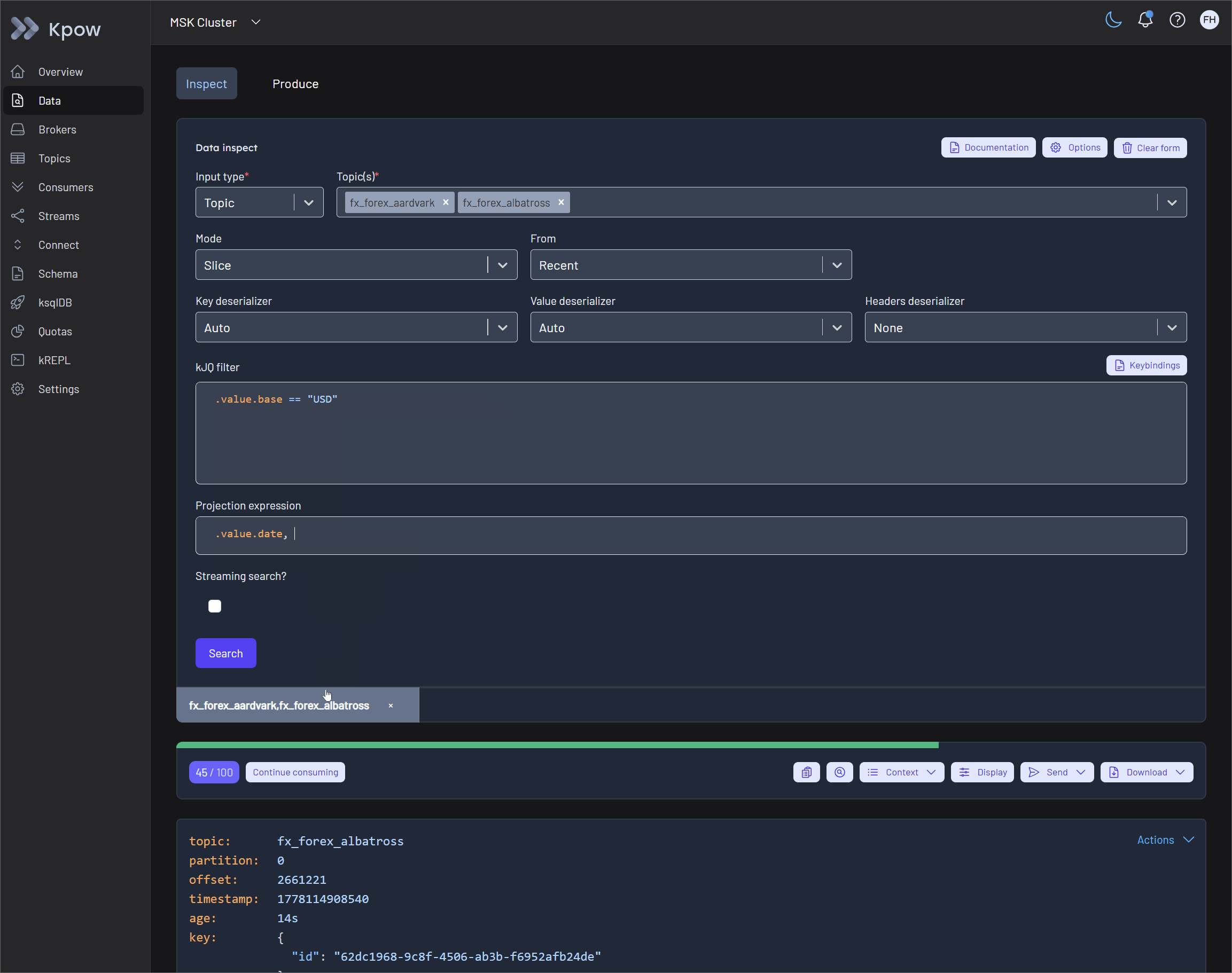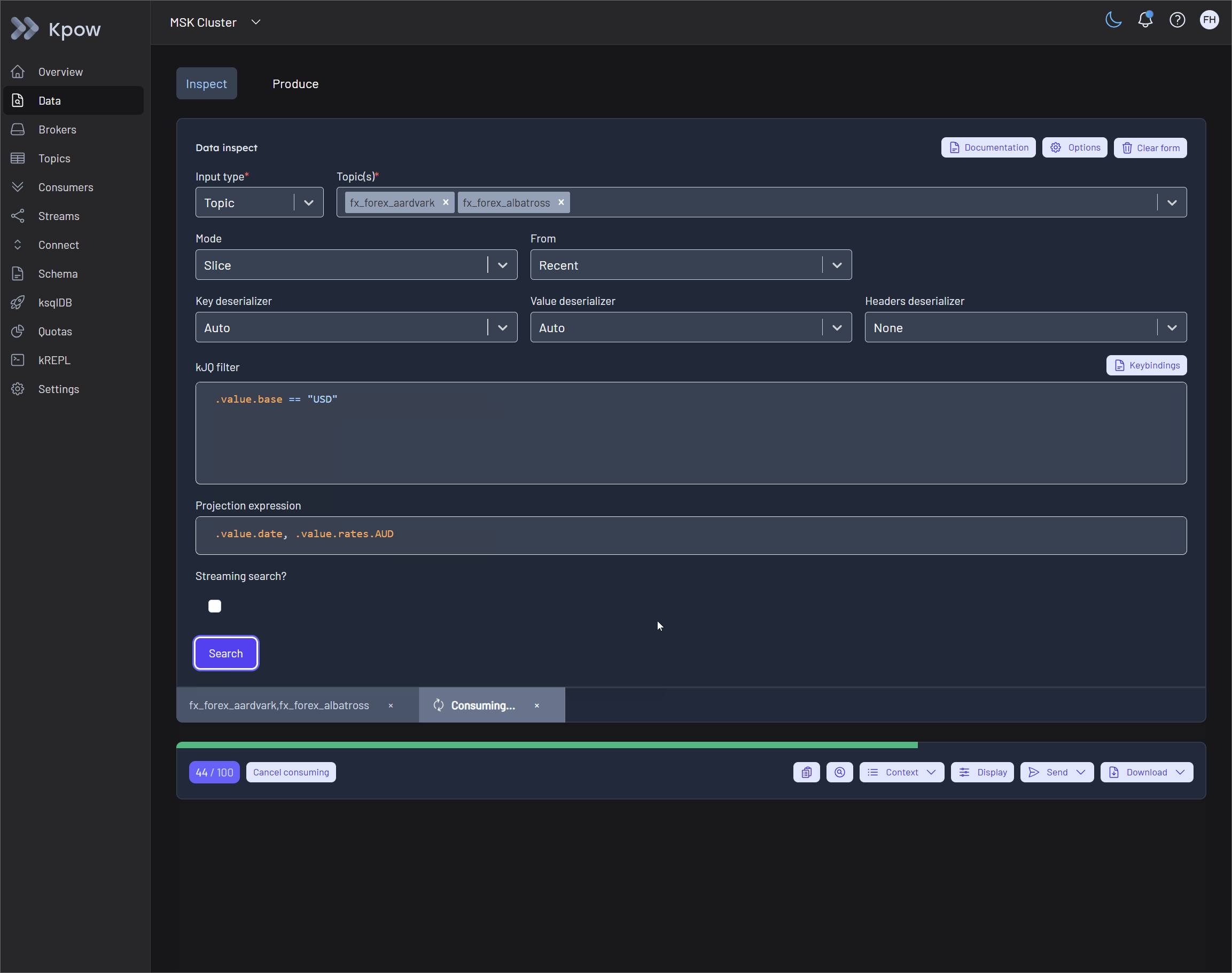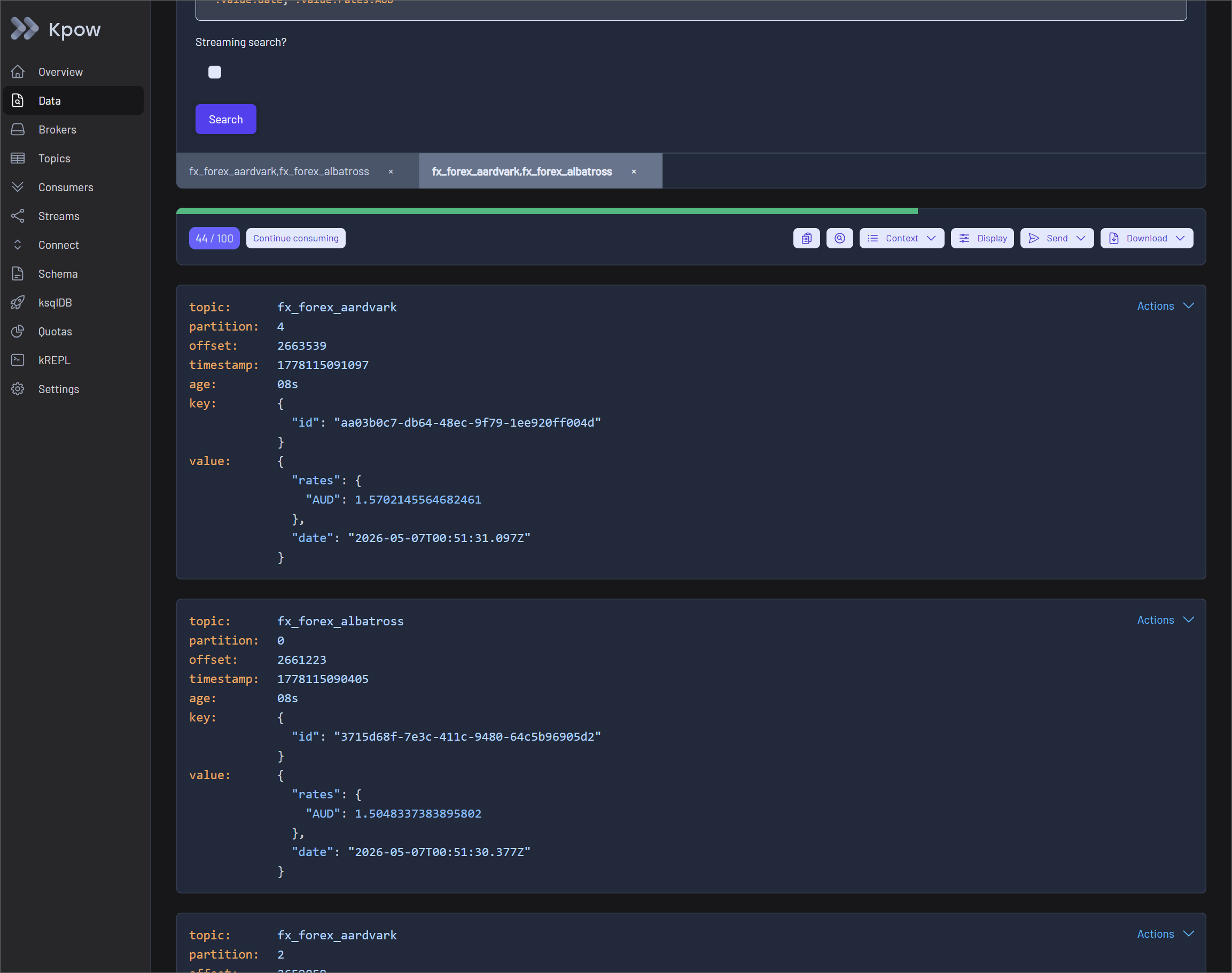
After isolating the relevant records, users can refine the visual output using Projection Expressions. This feature enables developers to extract specific fields from a record by providing a comma-separated list of kJQ object identifiers.
You can apply projection expressions to both the key and value fields of Kafka records. This is especially useful when dealing with extremely large payloads where you only need a subset of fields. For example, applying .value.user_id, .value.transaction.status to a massive JSON payload collapses the result into a clean, targeted subset of data. This shapes the output for immediate human readability and eliminates visual clutter.
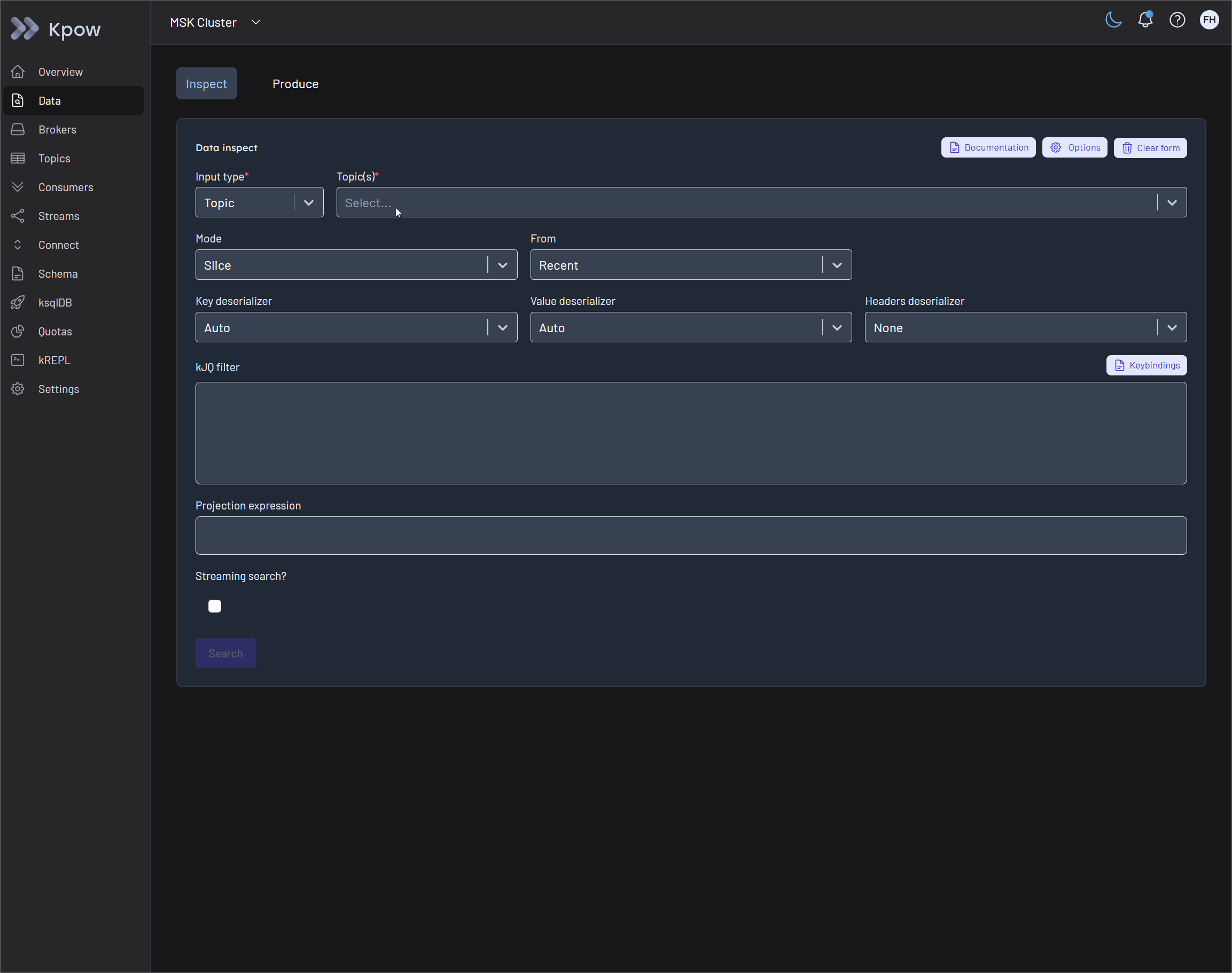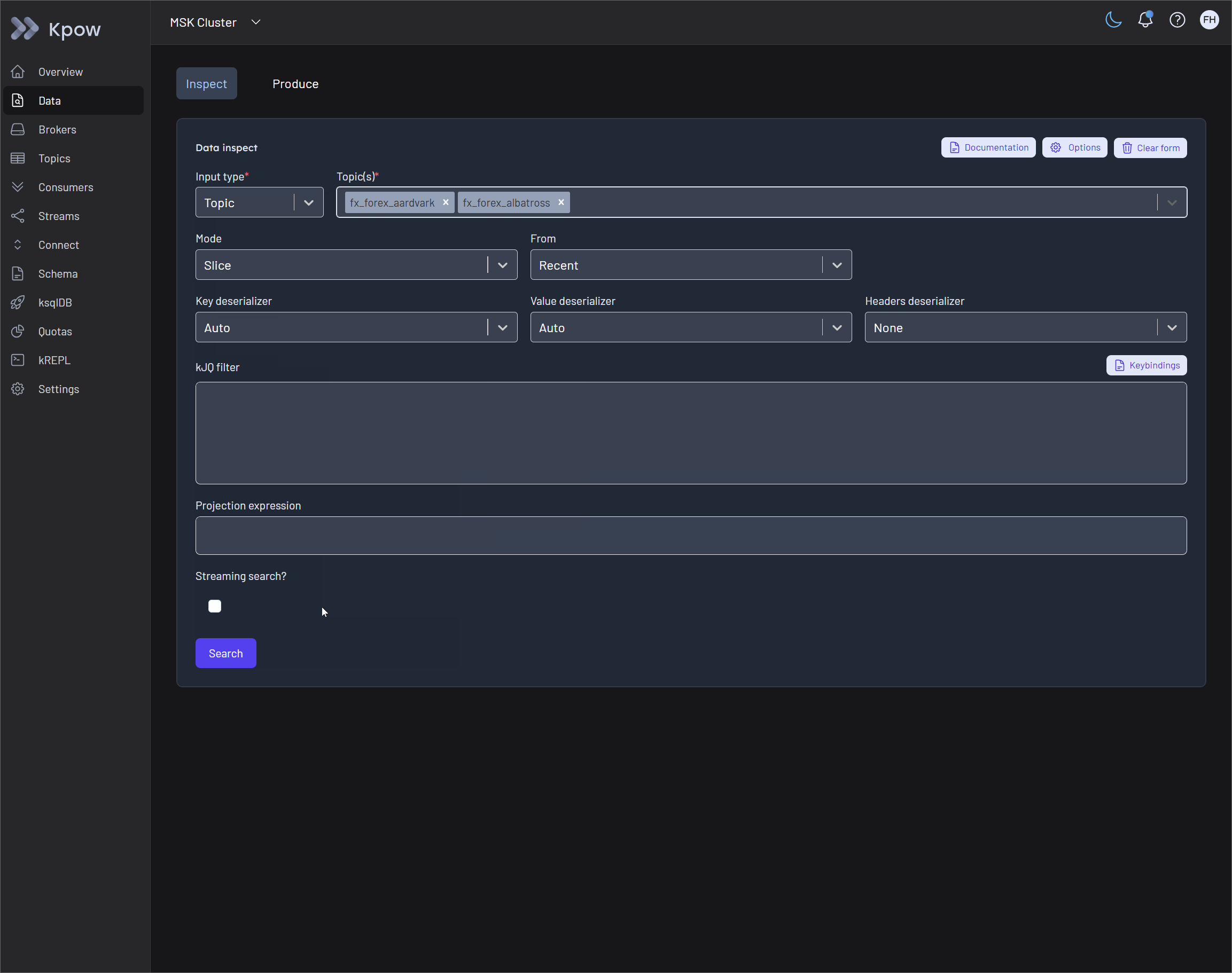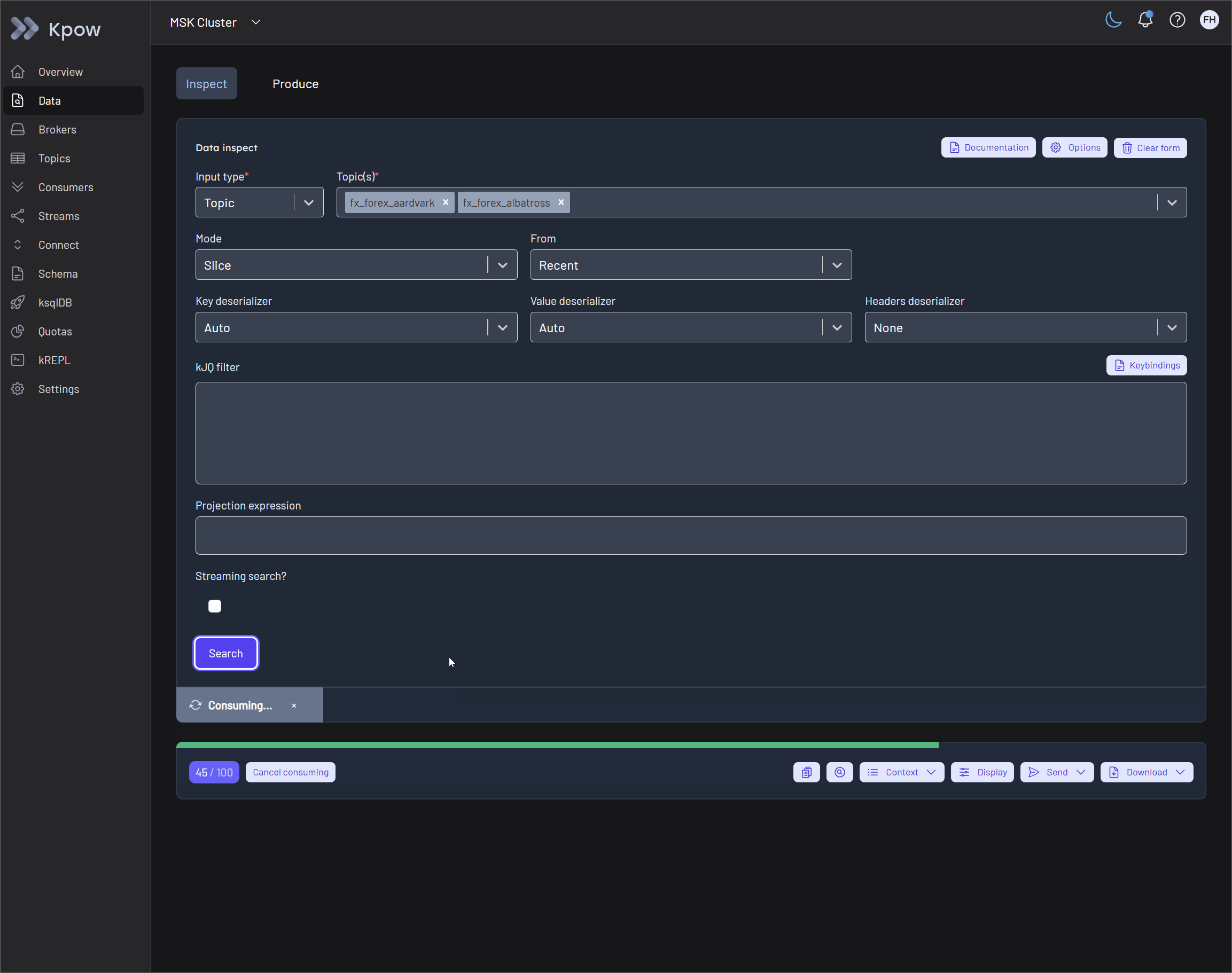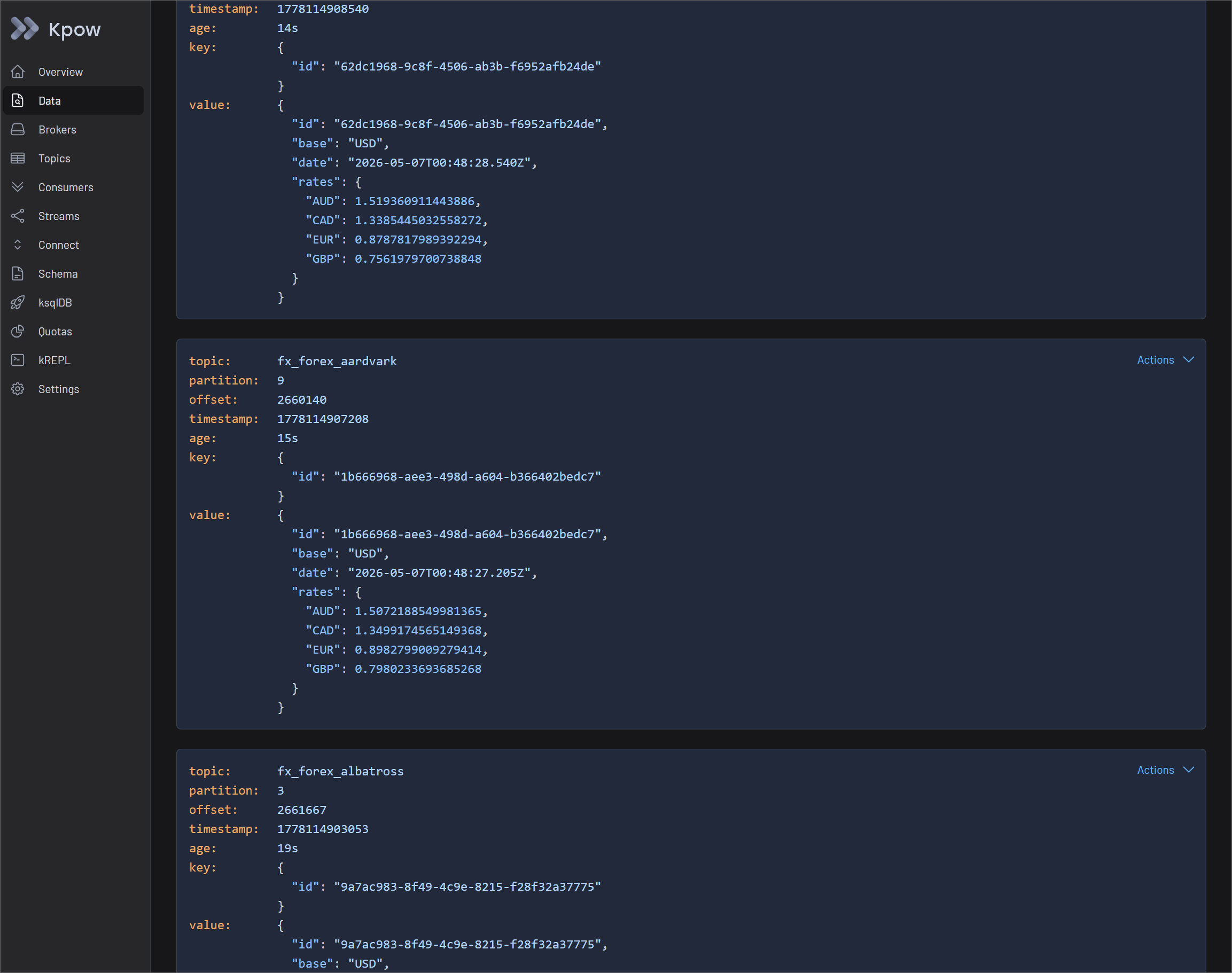
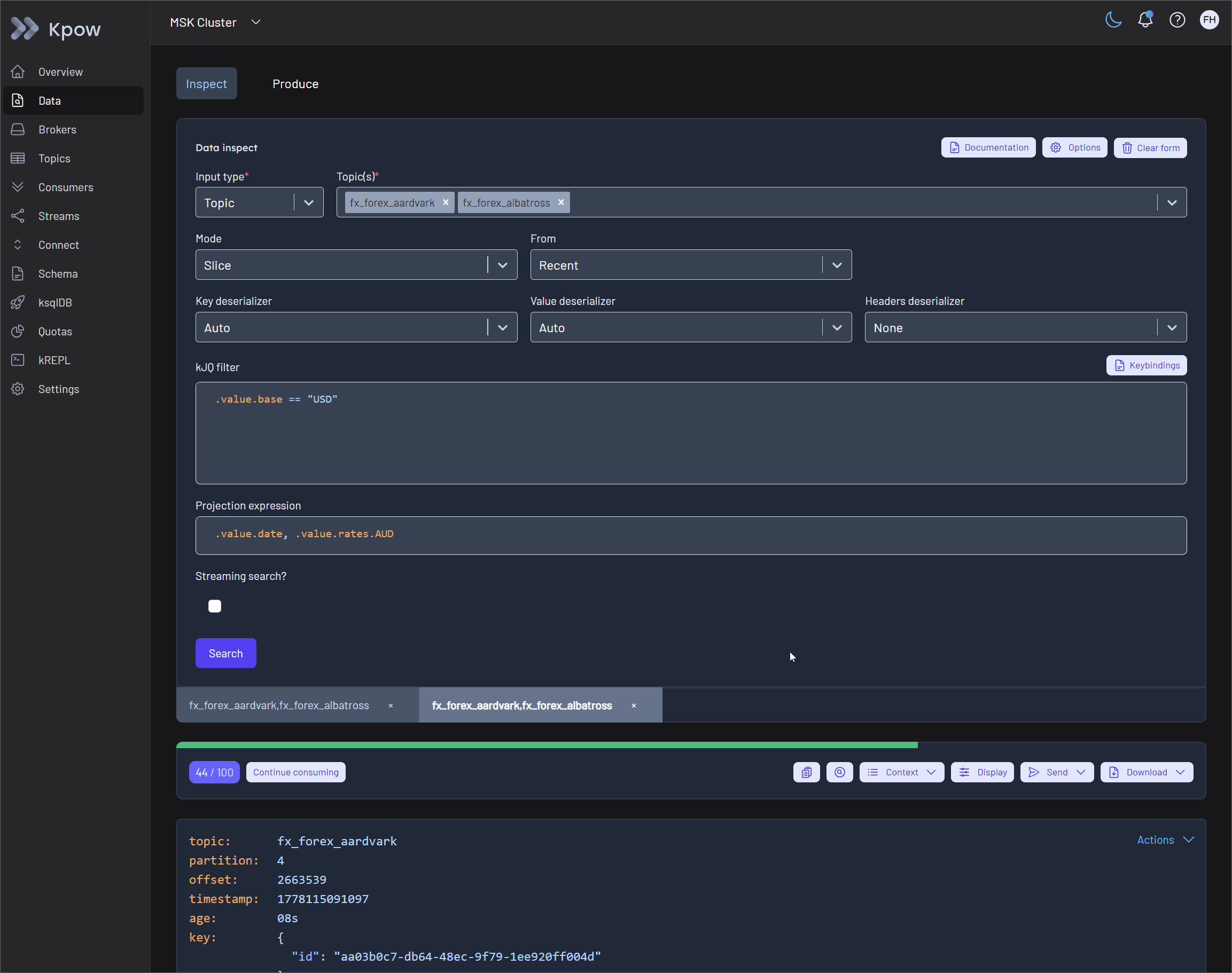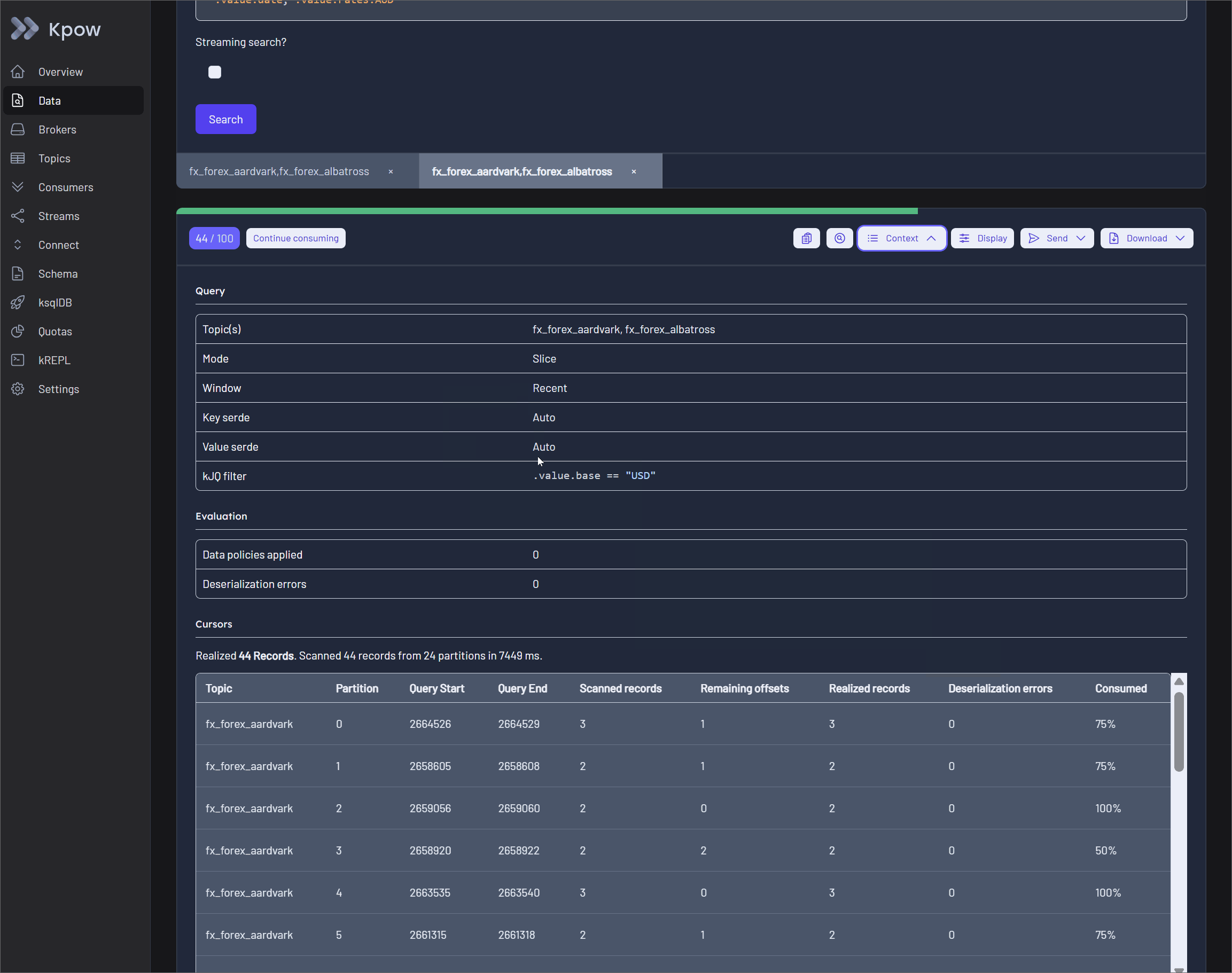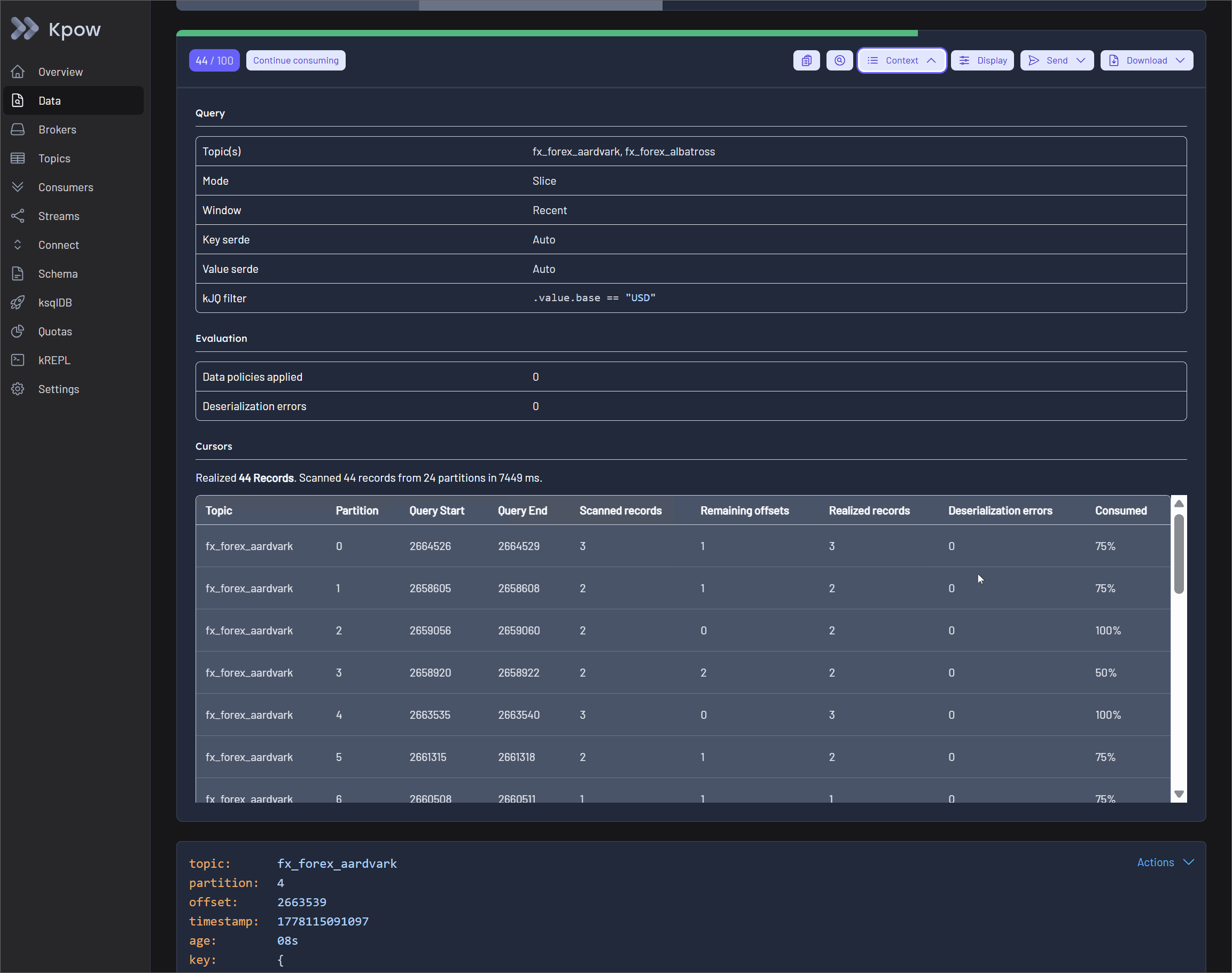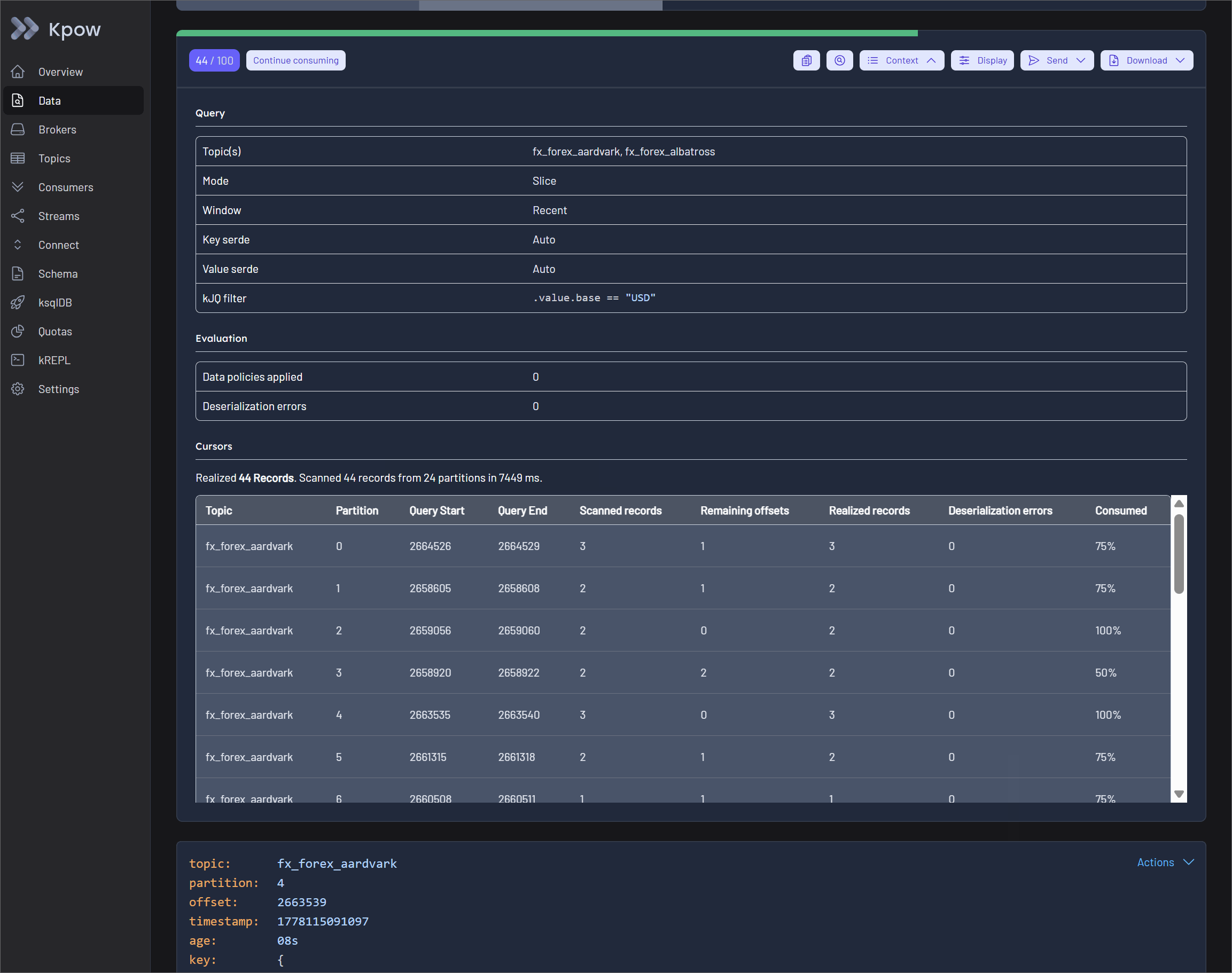
Transparent Query Context
To solve the problem of blind polling, Kpow surfaces detailed execution metrics directly in the UI. By expanding the Results Metadata Table within the query results toolbar, users gain instant feedback on partition-level scanning progress.
The table displays the query start and end offsets, the exact number of scanned records, and the remaining offsets available beyond the query window. This query transparency guarantees that engineers always know exactly how much of the topic has been searched and whether a partition is fully exhausted.
Optimizing Inspection for Enterprise Scale
To support fast, concurrent searches across large engineering teams, administrators can precisely tune Kpow’s underlying query infrastructure to match their specific cluster capacity and user demand.
Rather than relying on a rigid, one-size-fits-all approach, platform teams can adjust core configuration settings to balance developer velocity against broker load:
- Worker Concurrency: Administrators can scale the number of active workers handling search requests, allowing multiple users to execute complex queries simultaneously without experiencing queuing bottlenecks.
- Consumer Thread Pools: By increasing the number of consumer threads assigned to each worker, teams can enable parallel partition scanning to significantly improve overall query throughput.
- Resource Protection: Configurable query timeouts ensure that long-running searches do not monopolize cluster resources, while tunable poll durations allow administrators to optimize performance for topics containing exceptionally large messages.
Conclusion
In modern streaming architectures, the ability to inspect and search live data quickly is no longer optional. Kpow reduces the time between detecting an issue and understanding it. By eliminating configuration friction and providing tools to shape nested payloads, Kpow transforms Kafka data inspection into a streamlined, self-service workflow. Developers no longer need to wrestle with terminal outputs or guess schema formats. With transparent query context and optimized concurrent workers, application teams gain the baseline insight required to maintain complex streaming architectures.
Once foundational readability is established, teams can tackle more complex, high-pressure scenarios. In the next part of this series, Accelerating Incident Response: Advanced Filters, Streaming Search, and AI-Powered Queries, we will explore how Kpow accelerates investigations with advanced kJQ filtering, automates continuous data scanning, and leverages AI to generate complex query syntax instantly.
Next steps
Explore Kpow in your own environment with a free 30-day trial.
If you need assistance managing your Kafka environment, reach out to our engineering support team at [email protected].

