
KIP-932 Queues for Kafka: Bridging the Gap Between Streaming and Messaging
Table of contents


Software engineers have long debated the architectural trade-offs between event streaming platforms and traditional message queues. Do you need the durable, replayable logs of Apache Kafka, or the point-to-point, competing-consumer flexibility of RabbitMQ or AWS SQS? Often, the answer was to use both. This approach unfortunately led to complex and sprawling infrastructure.
With the introduction of KIP-932: Queues for Kafka, the Apache Kafka community has dramatically reshaped this conversation. By introducing "Share Groups", Kafka now natively supports cooperative, point-to-point message queuing without sacrificing its underlying distributed log architecture.
Blending queue semantics with log storage is not without its trade-offs. In this article, we will explore what KIP-932 is, the problems it solves, how to implement it, and the new operational complexities teams will need to manage as they adopt it.
About Factor House
Factor House is a leader in real-time data tooling, empowering engineers with innovative solutions for Apache Kafka® and Apache Flink®.
Our flagship product, Kpow for Apache Kafka, is the market-leading enterprise solution for Kafka management and monitoring.
Start your free 30-day trial or explore our live multi-cluster demo environment to see Kpow in action.
Key takeaways
- Share Groups break the 1:1 rule: Multiple consumers can now concurrently process messages from a single partition. This unlocks elastic scalability without the need for aggressive over-partitioning.
- Record-level acknowledgments: Instead of committing bulk offsets, consumers now acquire temporary locks on individual messages and acknowledge them upon successful processing.
- Elimination of head-of-line blocking: Slow-to-process messages no longer block the entire partition because other consumers in the Share Group can continue processing subsequent messages.
- New monitoring requirements: Managing states like "Acquired," "Available," and "Archived" requires new visibility paradigms. Factor House is actively building features to help engineers manage these new complexities as KIP-932 matures.
Background: Logs vs Queues in Kafka
To fully appreciate KIP-932, we must look at the historical divide between traditional messaging queues and event streaming logs.
Traditional Queues (e.g., RabbitMQ, ActiveMQ, SQS) operate on a point-to-point basis. When a message is published to a queue, multiple worker services can listen to that queue. When a worker grabs a message, it is hidden from others, processed, and then fundamentally destroyed or removed upon acknowledgment. This allows for massive, dynamic scalability of consumers. If your queue backs up, you simply spin up more worker instances.
Apache Kafka, on the other hand, is a distributed commit log. Messages are appended immutably to partitions. To read data, applications use Consumer Groups. In a traditional Consumer Group, Kafka enforces a strict rule: there can only be one active consumer per partition within a group.
If a topic has three partitions, you can only have three active consumers processing in parallel. If you spin up a fourth consumer, it sits completely idle. To scale up message processing throughput in Kafka, engineers have historically been forced to over-partition their topics. For instance, they might create 100 partitions just in case they need 100 consumers in the future. This taxes broker resources, increases ZooKeeper or KRaft metadata overhead, and complicates cluster management.
What is KIP-932 queues for Kafka?
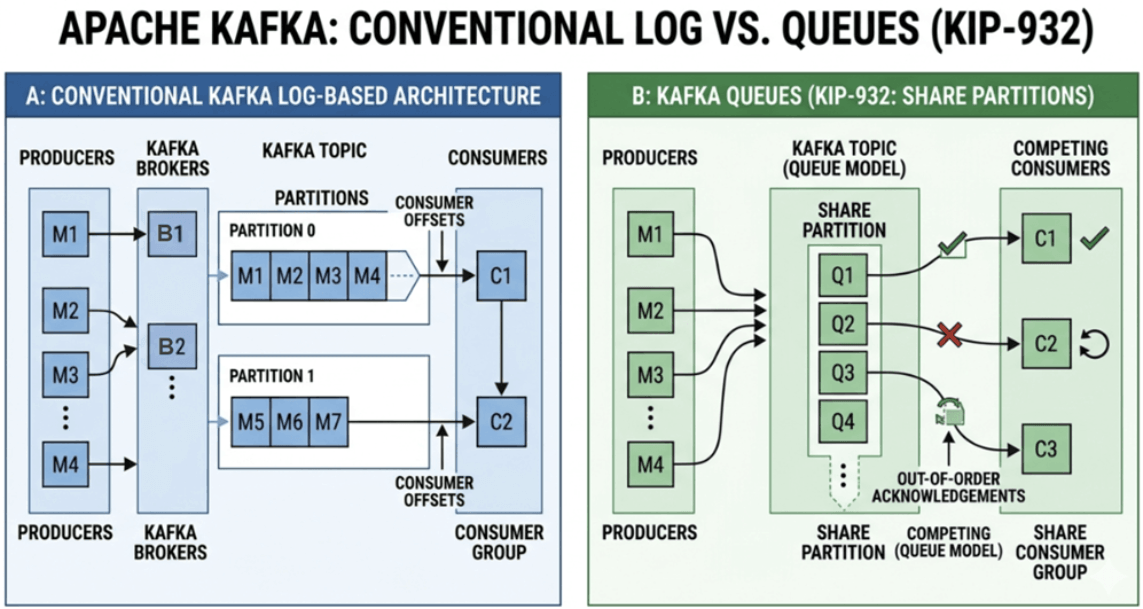
KIP-932 is a major architectural upgrade that brings point-to-point, cooperative queuing semantics natively to Apache Kafka. It introduces Share Groups, a new consumption model where multiple consumers can dynamically collaborate to process messages from the exact same partition.
Traditional Kafka Consumer Groups track progress using a single numerical offset to indicate how far down the log a consumer has read. In contrast, Share Groups track the state of individual records. When a consumer in a Share Group fetches a message, it does not just read it; it locks it. The message remains in the Kafka log, but the broker knows not to hand that specific message to any other consumer in the Share Group until the lock expires or the message is explicitly acknowledged.
This effectively turns a Kafka partition into a high-throughput, competing-consumer queue. It blends the best of both streaming and messaging worlds.
What does KIP-932 solve?
KIP-932 directly targets several long-standing pain points that developers face when building scalable microservices on top of Kafka.
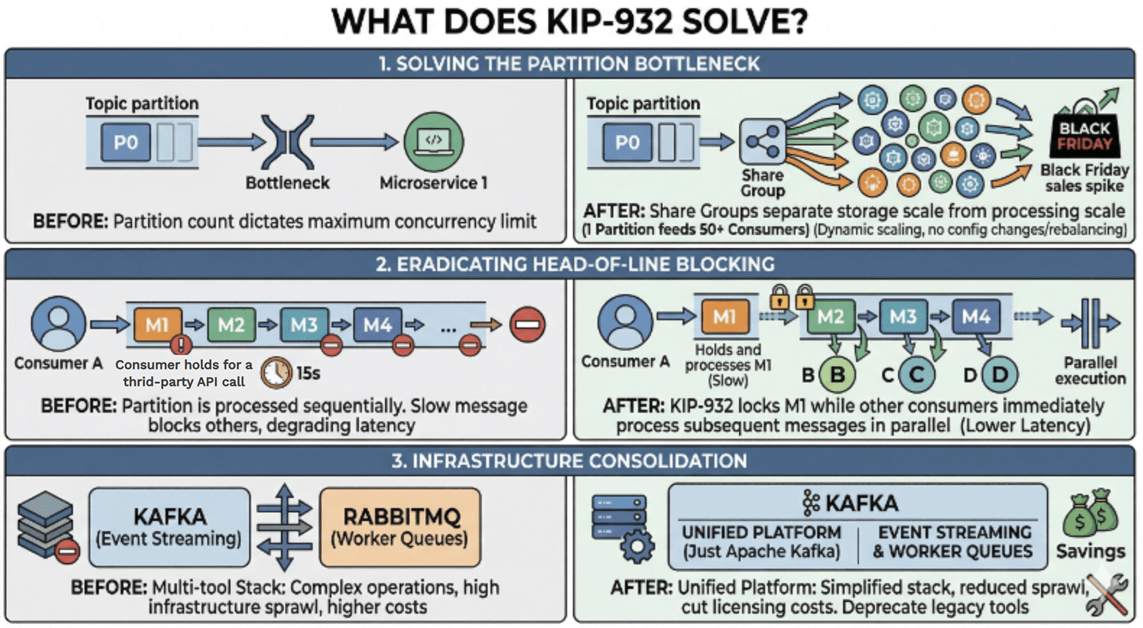
Solving the partition bottleneck
The most immediate benefit of KIP-932 is the separation of storage scale from processing scale. Previously, your partition count dictated your maximum concurrency limit. With Share Groups, you can have a single partition topic being processed concurrently by 50 different microservice instances. Applications can now dynamically scale horizontally in response to traffic spikes, such as Black Friday sales. Administrators no longer need to modify topic configurations or rebalance partition leaders.
Eradicating head-of-line blocking
In a traditional consumer group, partitions are processed sequentially. If Consumer A reads Message 1, and processing that message requires a slow third-party API call taking 15 seconds, all subsequent messages are stuck waiting. This "head-of-line blocking" degrades latency. With KIP-932, Consumer A can lock and process Message 1 while other consumers immediately fetch and process the next messages concurrently.
Infrastructure consolidation
Historically, architectures required a two-tier messaging strategy. Kafka was used as the central nervous system for high-throughput, durable event streaming, while tools like RabbitMQ were deployed at the edge for task routing and worker queues. KIP-932 enables teams to deprecate legacy messaging systems. This reduces infrastructure sprawl, cuts licensing costs, and simplifies the tech stack to just Apache Kafka.
How does KIP-932 work in Kafka?
Under the hood, KIP-932 fundamentally alters how Kafka brokers and clients agree on what data has been read. It achieves this via Record-Level Acknowledgement and Acquisition Locks.
When a Share Group is utilized, records cycle through distinct states:
- Available: The message is sitting in the partition and is ready to be processed.
- Acquired: A Share Consumer fetches the message. The broker applies a temporary lock (configurable, but defaulting to 30 seconds). During this window, the message is invisible to other consumers in the same Share Group.
- Acknowledged: The consumer successfully processes the message and sends an
ACCEPTacknowledgment to the broker. The message is marked as complete for that group. - Released or Archived: If the consumer fails and sends a
REJECT, or if the lock times out because the consumer crashed, the broker releases the lock. This returns the message to the Available state for another consumer to try. If it hits a predefined retry limit, it transitions to Archived (Kafka's native equivalent of a Dead Letter Queue).
What complexities does KIP-932 introduce?
While the benefits of Share Groups are immense, they introduce entirely new paradigms of state and error handling. Traditional Kafka monitoring strategies will no longer suffice.
Obscured State Management and Visibility
For years, monitoring Kafka consumers meant tracking a single metric: Consumer Lag. If the partition log ended at offset 100, and your consumer was at offset 90, your lag was 10. It was simple arithmetic.
With Share Groups, a group might have Acknowledged offsets 1, 2, 4, and 7, while offsets 3 and 6 are currently Acquired (locked), and offset 5 is Available. The concept of a single "lag" number is obsolete; you now have an in-flight state matrix.
Factor House is actively building the tools to manage the new complexities introduced by KIP-932. Because Share Groups operate on an entirely different set of methods and properties at the AdminClient level, traditional monitoring tools that rely on simple offset math will essentially break or fail to show the complete picture. Recognizing that Share Groups represent an "entirely new world," our engineering team is currently designing a dedicated, purpose-built experience within our market-leading toolkit, Kpow. Rather than forcing this new paradigm into legacy consumer group views, our goal is to provide a tailored interface that translates this complex state matrix into clear, actionable insights. This ensures your operations team will not be left guessing about in-flight states.
Dealing with Poison Pills and Archiving
In standard Kafka, a "poison pill" (a malformed message that crashes your consumer) would halt partition processing entirely until an engineer intervened. KIP-932 automatically handles this via the group.share.delivery.attempt.limit configuration. If a message continually crashes consumers, its lock expires, it gets retried, and eventually, it is moved to the Archived state.
However, Kafka natively provides very little tooling to inspect or manage these Archived messages once they are sidelined. At Factor House, we are carefully evaluating how to bridge this gap. As KIP-932 matures and the APIs stabilize, we are looking at how to extend Kpow's industry-leading data inspection and troubleshooting workflows to support these new archiving mechanics. Our vision is to ensure engineers will have the seamless ability to isolate, inspect, and recover archived records just as easily as they manage standard topic data today.
Loss of Strict Ordering Guarantees
Because multiple consumers are pulling from the same partition concurrently, strict chronological ordering is completely broken. If order matters for your business logic (e.g., processing an "Account Created" event before an "Account Updated" event for the same user ID), Share Groups are not the right tool. Engineers must carefully evaluate their domain logic to ensure their microservices are genuinely idempotent and order-independent before migrating to KIP-932 queues.
Ecosystem Maturity
KIP-932 requires brand new API classes (like KafkaShareConsumer in Java) to handle the new acknowledgment protocols (ACCEPT, RELEASE, REJECT). While Confluent and the Apache community have prioritized the Java ecosystem, wrappers like librdkafka (which power Python, Go, C++, and .NET) are taking longer to catch up. Organizations with polyglot architectures will face a transition period where only their Java-based microservices can leverage Share Groups. This could potentially lead to fragmented architectural patterns in the short term.
How to implement KIP-932 queues for Kafka Share Groups
Implementing Share Groups requires a modern Kafka deployment and specific client-side code changes. Instead of relying on a standard KafkaConsumer, your application must utilize the new Share Group APIs.
Prerequisites:
- Apache Kafka 4.0 or newer.
- A compatible client (currently Java via
KafkaShareConsumer).
Step 1: Enable Share Groups on the Broker
Ensure your broker configurations have the share group protocols enabled. This is enabled by default in newer KRaft-based Kafka releases.
Step 2: Instantiate the Share Consumer
In your Java application, replace your traditional consumer with the new KafkaShareConsumer class.
Step 3: Configure the Group ID
Instead of using group.id, you bind your consumers together using the share.group.id property.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("share.group.id", "my-first-share-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaShareConsumer<String, String> consumer = new KafkaShareConsumer<>(props);
consumer.subscribe(Collections.singletonList("kip932-demo-topic"));Step 4: Handle Acknowledgements
Update your application code logic to utilize the new record-level APIs. When a record is processed, explicit acknowledgments dictate what happens to the message next.
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
try {
// Process the message
System.out.printf("Processing key = %s, value = %s%n", record.key(), record.value());
// Explicitly accept the record upon success
consumer.acknowledge(record, AcknowledgeType.ACCEPT);
} catch (Exception e) {
// Reject the record so it can be retried by another consumer
consumer.acknowledge(record, AcknowledgeType.REJECT);
}
}
// Commit the acknowledgments to the broker
consumer.commitSync();
}By deploying multiple instances of this Java application, you will instantly see Kafka distribute the messages concurrently among the active instances. This completely bypasses the traditional partition limits.
Our take at Factor House
KIP-932 is undeniably a milestone for Apache Kafka. By successfully merging event streaming with point-to-point queuing, it empowers engineering teams to vastly simplify their infrastructure and scale worker processes dynamically without jumping through the hoops of over-partitioning.
We believe that operational tooling must evolve at the same pace as the infrastructure. The transition from simple offset tracking to complex, record-level state management introduces significant blind spots if teams rely on legacy monitoring tools. We are incredibly excited about this new era of Kafka, but we also recognize that such a fundamental shift requires equally evolved tooling.
Because Share Groups introduce an entirely new set of methods and properties, we are actively developing the next generation of Kpow features to tackle this challenge head-on. Rather than trying to patch over legacy consumer group views, we are building a completely distinct and tailored UI experience to illuminate these new mechanics. Stay tuned as we continue to roll out dedicated support to help you safely and effectively navigate this exciting new streaming landscape.
Next steps
Explore Kpow in your own environment with a free 30-day trial.
If you need assistance managing your Kafka environment, reach out to our engineering support team at support@factorhouse.io.