
Triage, repair, and replay: integrated Kafka remediation workflows

Table of contents


In the second part of this series, we demonstrated how combining advanced filtering, artificial intelligence, and streaming search accelerates investigations to help teams respond to incidents quickly. However, locating bad data is only half the battle. Once an issue is identified, engineering teams must take action to fix the pipeline.
Resolving a stalled consumer, recovering from a downstream database crash, or fixing a dead-letter queue (DLQ) message requires managing both the consumer state and the data payload itself. This article explores the friction inherent in generic recovery workflows and demonstrates how Kpow unifies data extraction, state management, and payload correction into a single integrated process.
This is Part 3 of the Kafka Data Management with Kpow: Unlocking Engineering Productivity series. You can read the full strategy in the main series article and access the associated posts as they become available:
- Part 1: Foundational Kafka Data Inspection: Shaping Payloads and Optimizing Visibility
- Part 2: Accelerating Incident Response: Advanced Filters, Streaming Search, and AI-Powered Queries
- Part 3: Triage, Repair, and Replay: Integrated Kafka Remediation Workflows (This article)
- Part 4: Defense in Depth: Unifying RBAC and Data Policies for Transparent Governance
About Factor House
Factor House is a leader in real-time data tooling, empowering engineers with innovative solutions for Apache Kafka® and Apache Flink®.
Our flagship product, Kpow for Apache Kafka, is the market-leading enterprise solution for Kafka management and monitoring.
Start your free 30-day trial or explore our live multi-cluster demo environment to see Kpow in action.
Problem: Fragmented Pipeline Repair
Fixing data pipelines extends beyond simply identifying a schema mismatch. A single malformed record (a poison pill) can crash a consumer thread. This causes the thread to catch the error, seek back to the problematic offset, and retry in an infinite loop. Because other partitions process normally, aggregated metrics often mask the failure, allowing lag to spike silently on a single partition.
Alternatively, a downstream sink failure might require a complete historical data replay. Resolving these diverse issues requires identifying the exact malformed payload, modifying consumer group offsets, and fixing the underlying data. Currently, these tasks exist in completely disconnected operational silos.
Limitations of Siloed Recovery
Generic workflows introduce severe friction when pipelines break. Developers are forced to context-switch, often writing one-off scripts to hunt down serialization errors or extract records for analysis.
Meanwhile, repairing the pipeline state requires administrative access. Developers must file tickets and wait for platform engineers to run the Kafka Consumer Group CLI commands manually to reset or skip offsets. This disconnected ticketing process creates dangerous race conditions. If the consumer application restarts before the manual CLI command executes, the command will fail or conflict with the active consumer state. Furthermore, this process only addresses the consumer offset, leaving the actual malformed data uncorrected and missing from the downstream system.
Integrated Remediation with Kpow
Kpow eliminates the Remediation Gap by consolidating data inspection, consumer state management, and payload correction into a single interface. This allows operators to seamlessly transition from finding an issue to completely resolving it.
Isolating Malformed Data
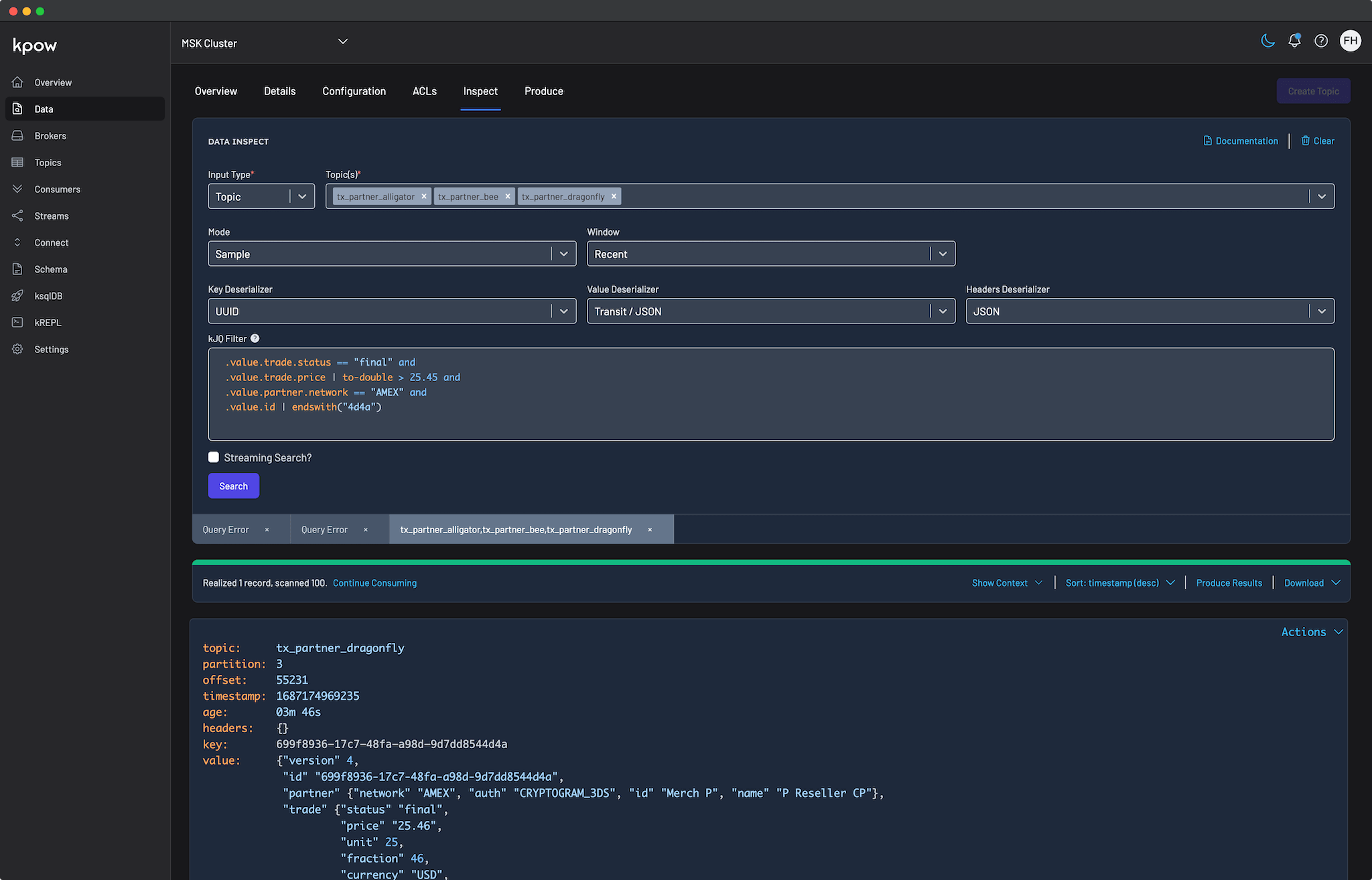
When a consumer stalls, operators can move directly from the stalled partition to the underlying data. By opening the Consumer Details tab, engineers can spot rapidly accumulating lag on a specific partition. Clicking the Inspect data action instantly opens the Data Inspect UI, pre-filtered to the affected partition, where operators can quickly apply a kJQ filter to pinpoint the exact offset causing the blockage.
Alternatively, if the problematic offset is unknown, Kpow provides powerful Deserialization Options to cut through the noise of healthy traffic. By setting the strategy to Poison only, operators can scan the topic to instantly filter out all successfully parsed records, isolating only the malformed data (such as an unexpected string instead of a required integer) that crashed the consumer.
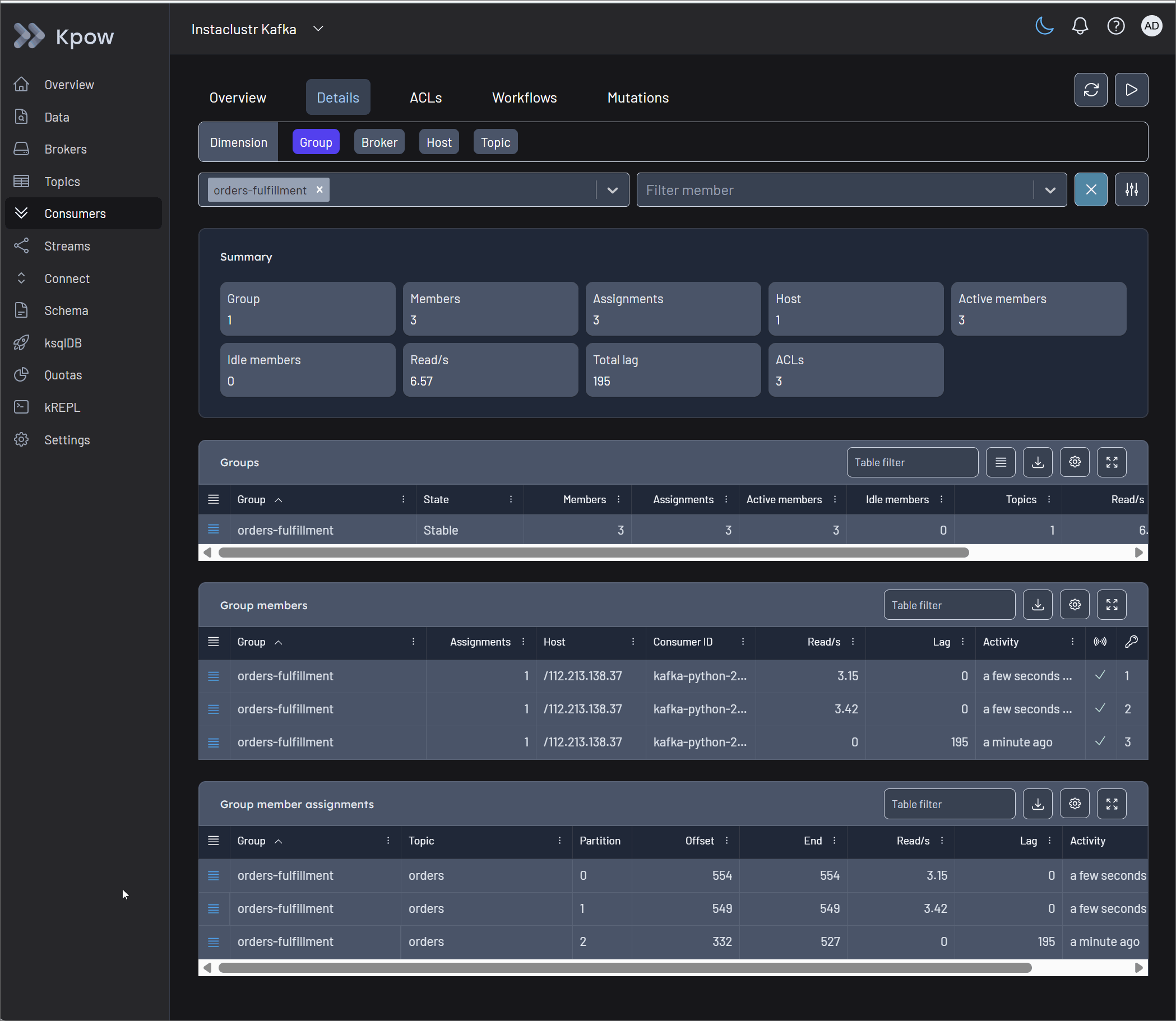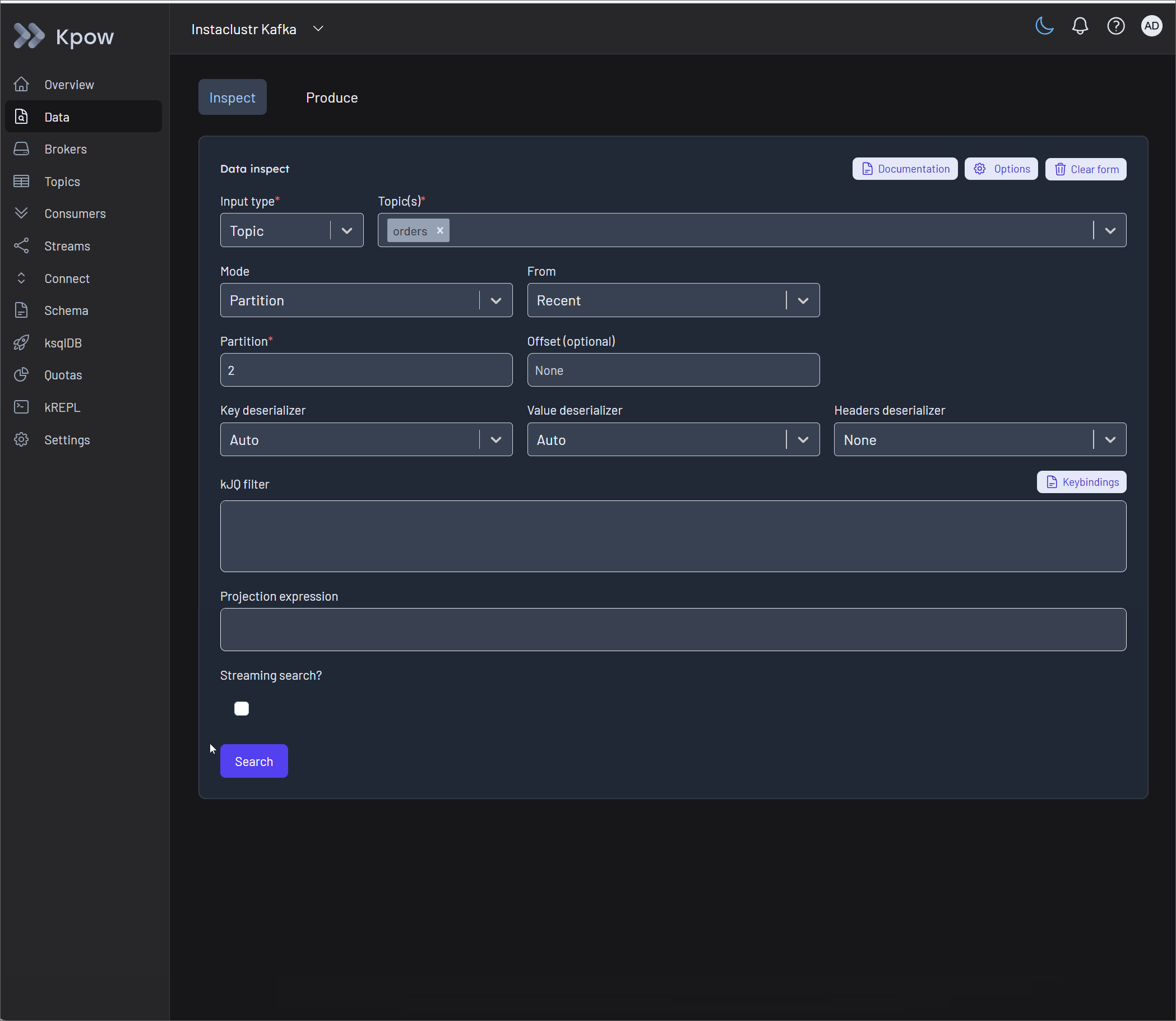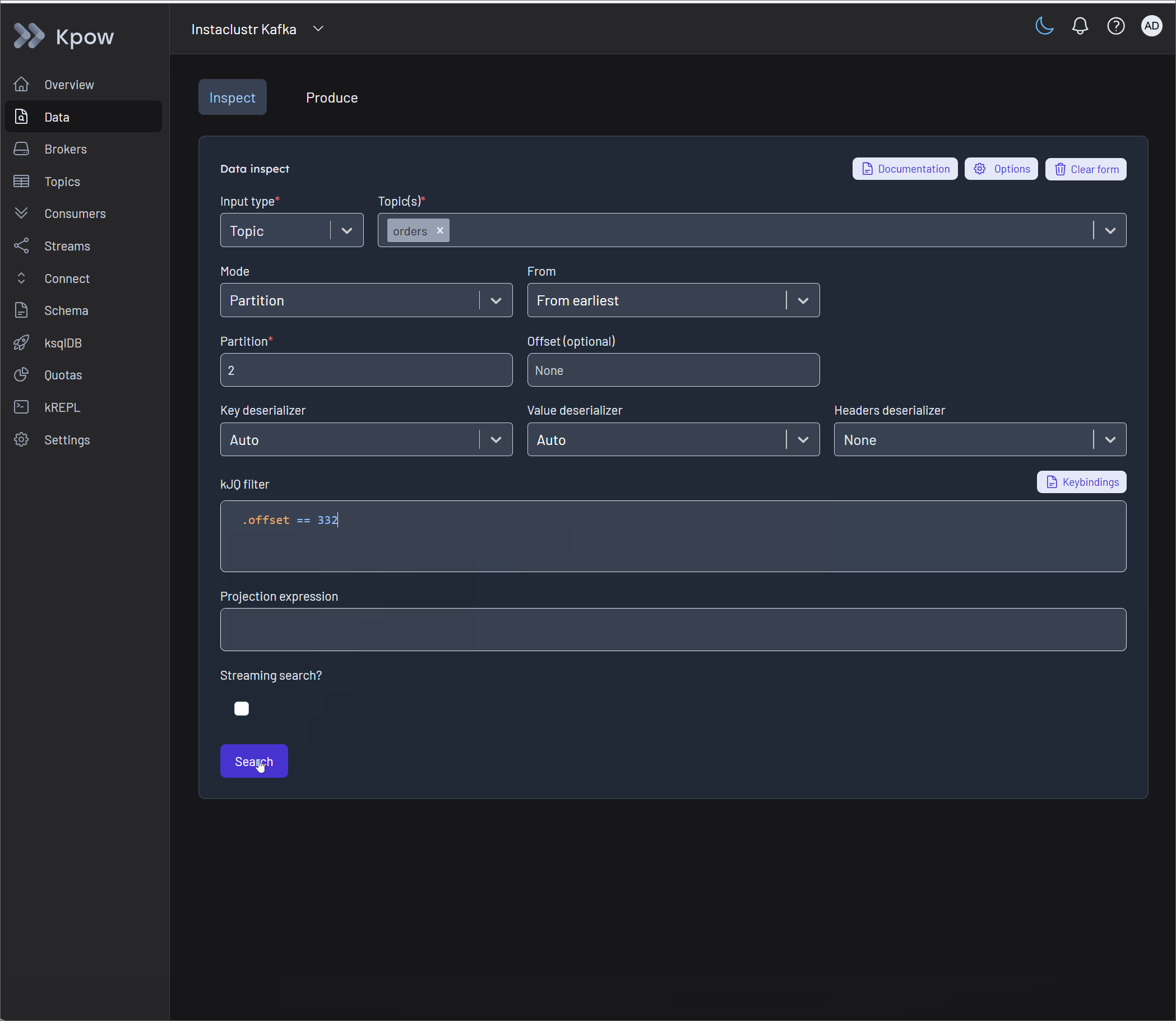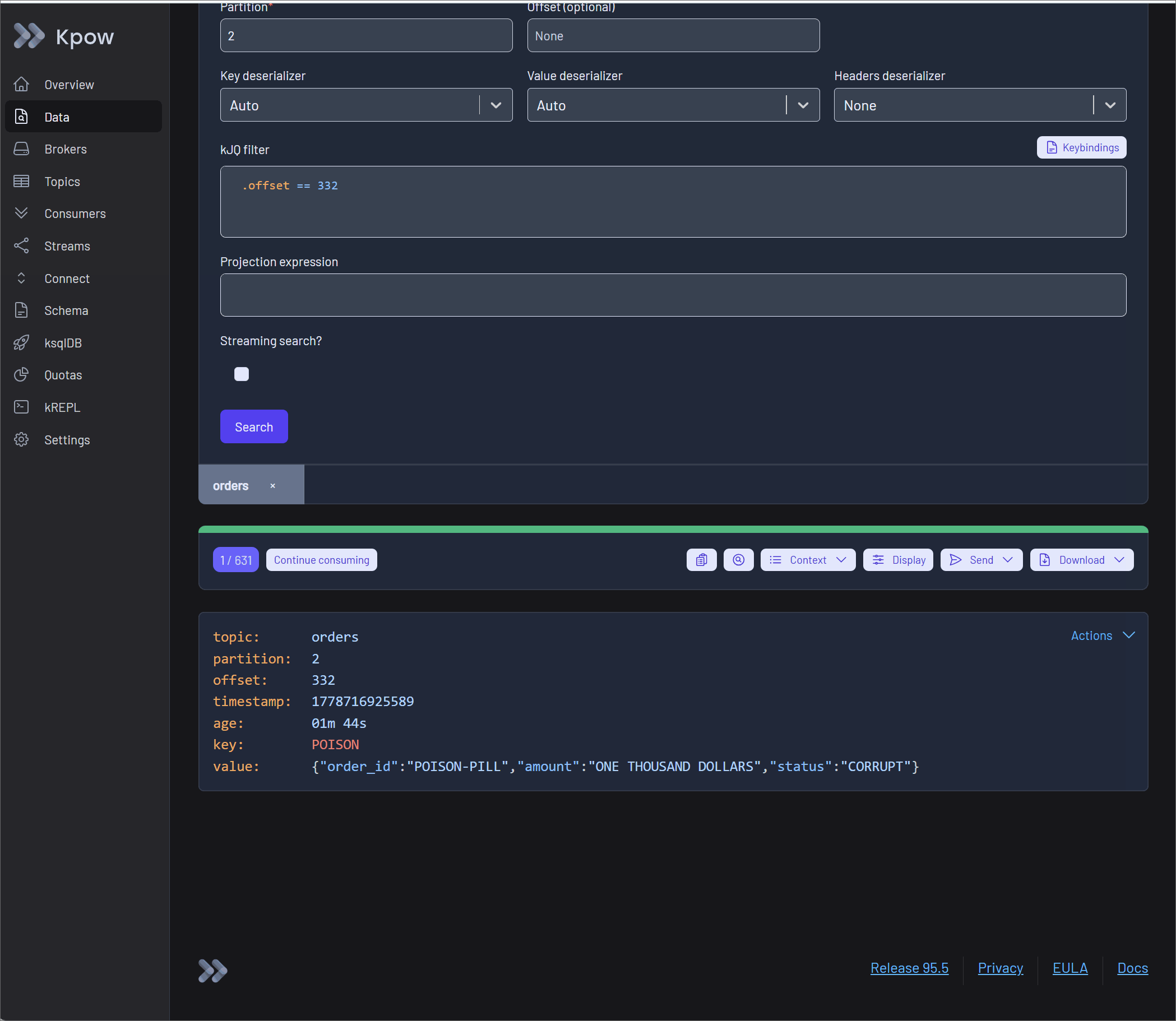
Unblocking Consumers with Group Actions
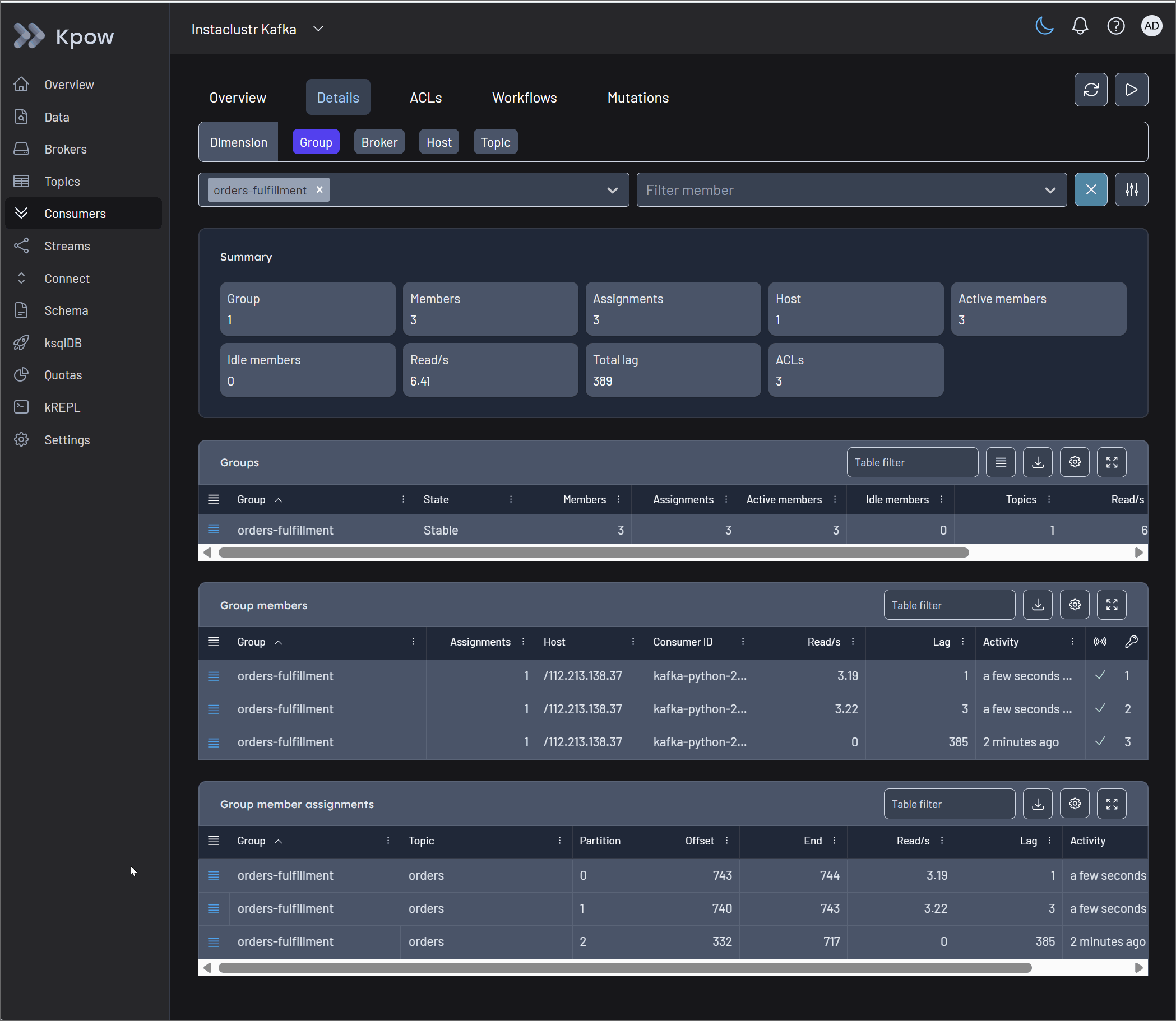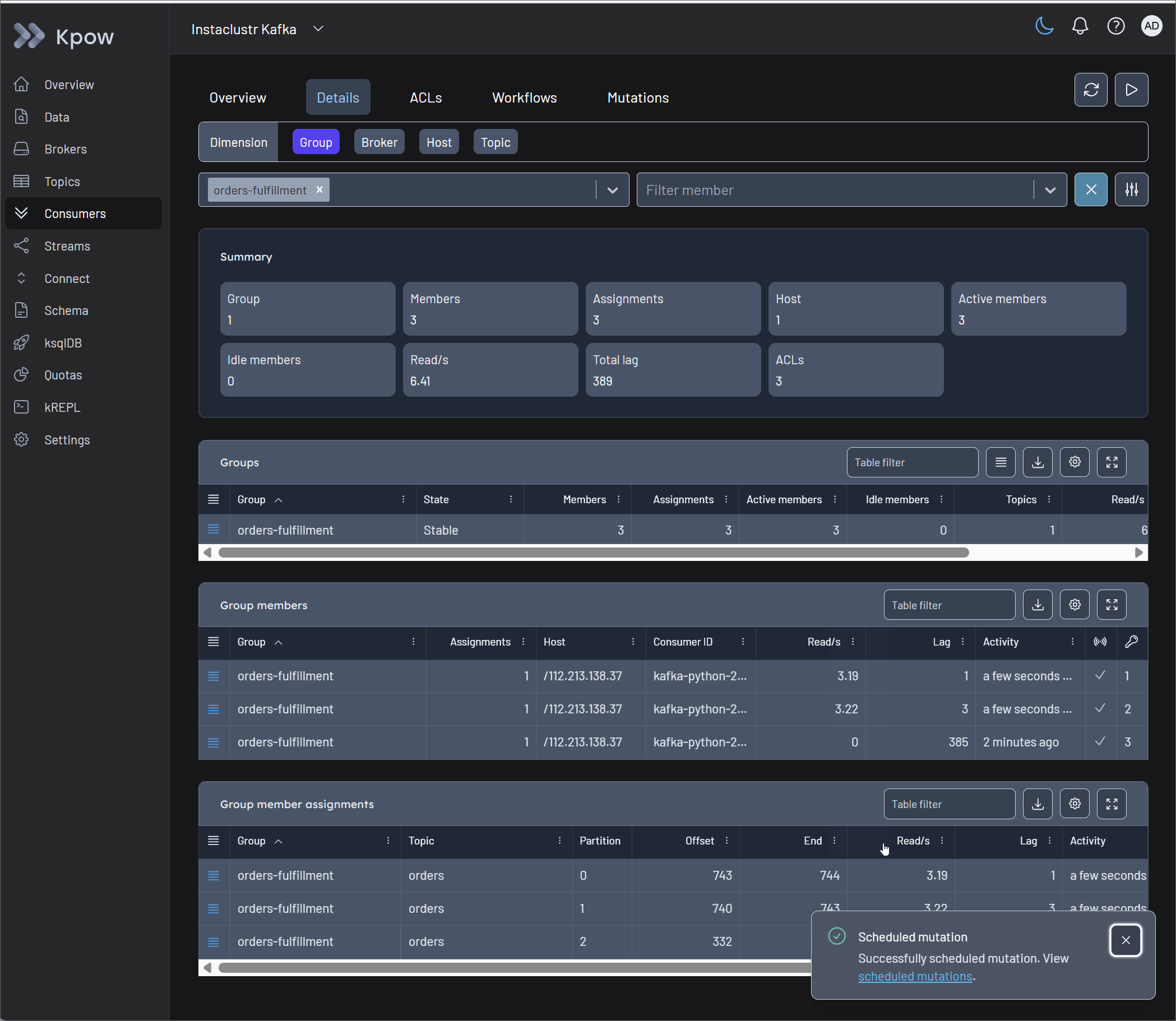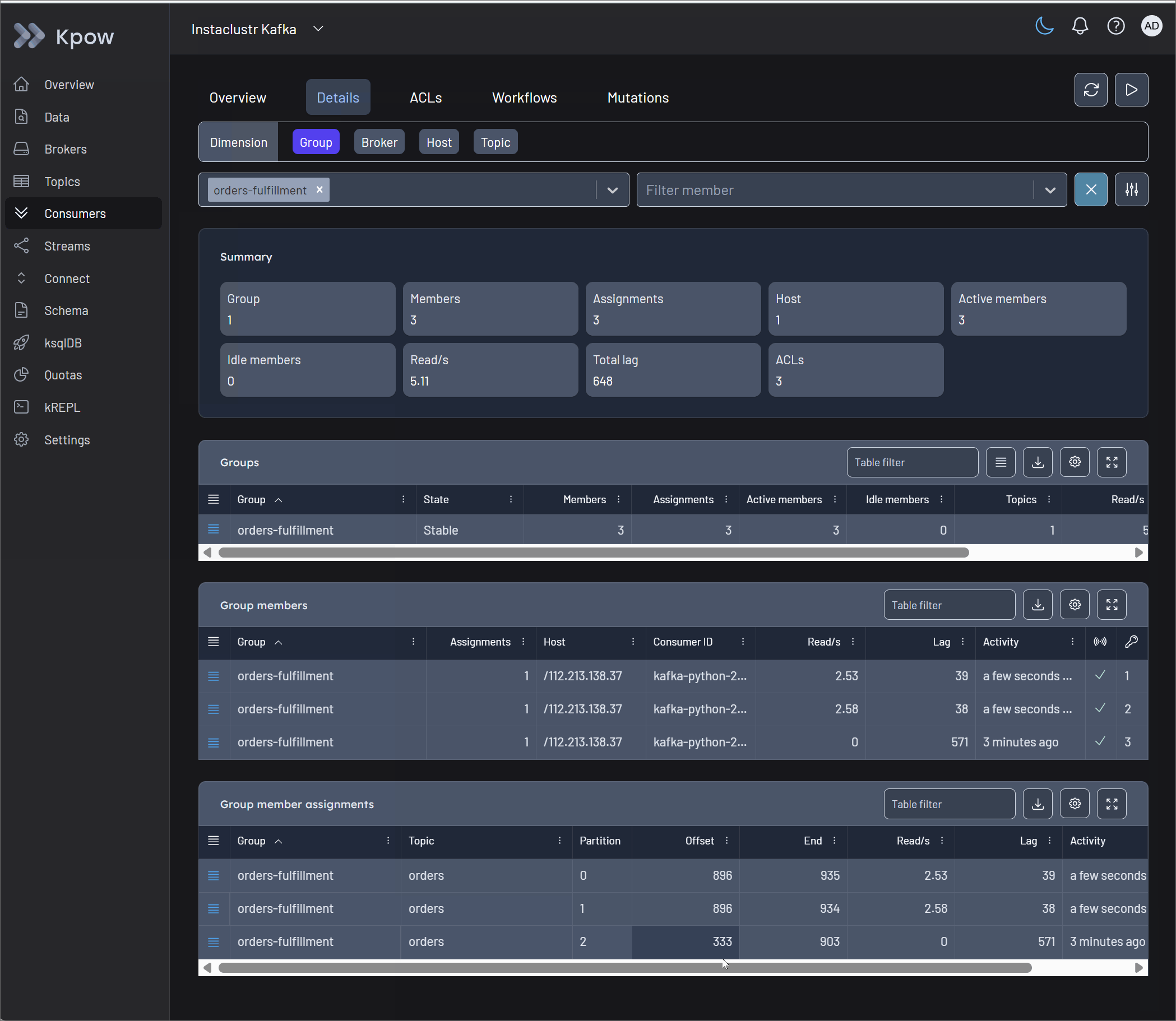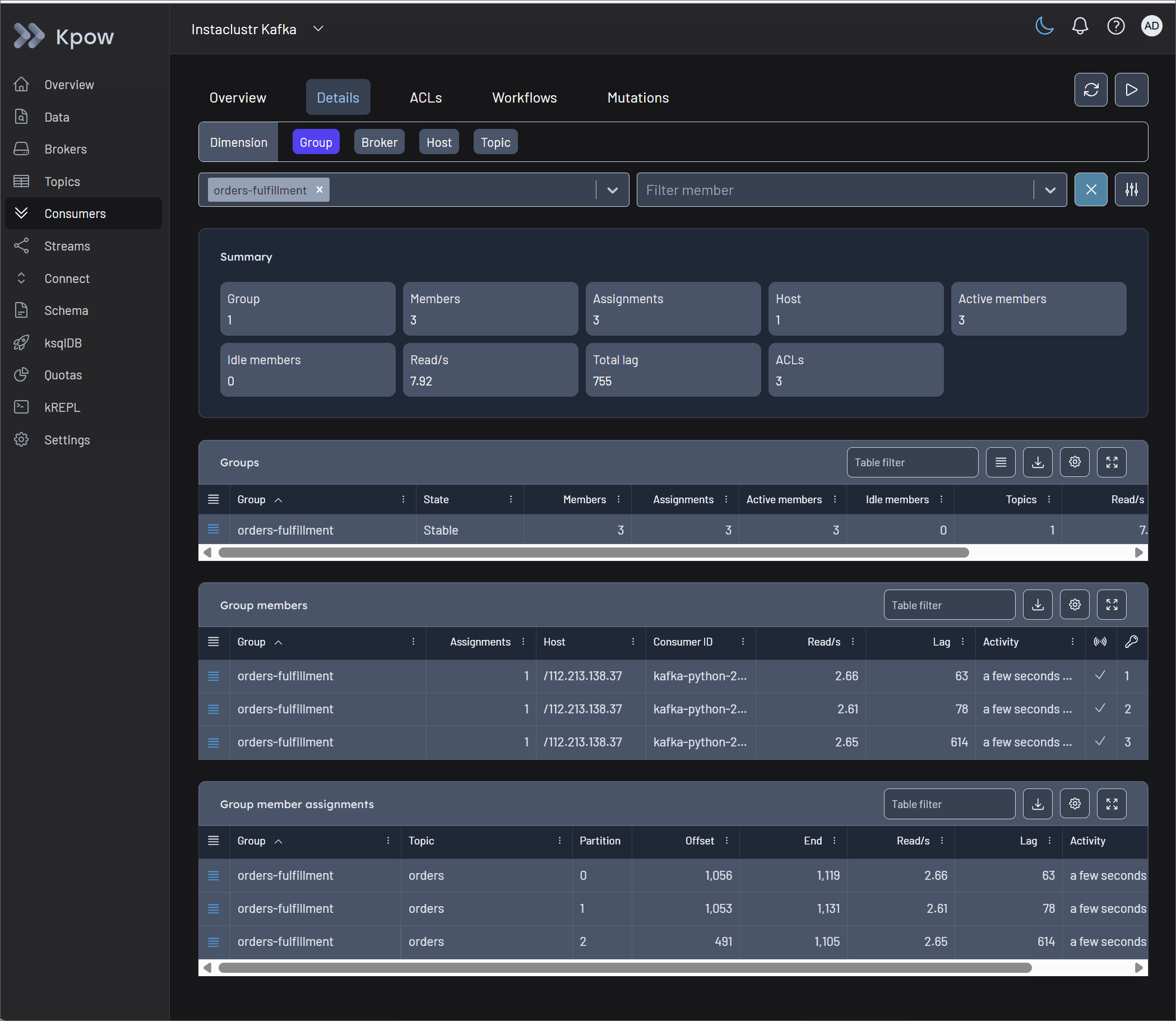
Once the problematic offset is identified, operators must unblock the pipeline safely. Kpow's Consumers UI provides robust state management capabilities. From the action menu, operators can execute a Skip offset at the partition level to immediately bypass the single poison pill. Kpow also supports Clear offset and Reset offset actions, which allow engineers to rewind a group to a specific offset, timestamp, or precise datetime to replay data after a sink failure.
Crucially, Kpow protects the integrity of the cluster through Scheduled Mutations. Rather than forcing manual CLI commands that clash with active consumers, Kpow safely schedules the offset change. The platform waits for the consumer group to scale down to an EMPTY state before automatically executing the mutation, completely preventing state conflicts and race conditions.
Repairing and Re-injecting Payloads
Skipping a poison pill unblocks the consumer, but the data is still lost to the downstream system. To achieve complete remediation, teams must correct the payload and re-inject it into the pipeline.
Kpow enables this through native UI routing. By highlighting the isolated bad record in the Data Inspect view and selecting Produce from the drop-down menu, operators route the message directly into the Data Produce form. The form opens pre-populated with the record's details.
Developers can execute a quick manual edit to the JSON payload (for example, fixing an invalid "amount": "ONE THOUSAND DOLLARS" field by replacing it with numeric 100) and produce the corrected message. This visually proves that the data was not just skipped, but successfully repaired and re-injected. For offline auditing, Kpow also offers robust downloading options to extract the problematic records in CSV, JSON, or EDN formats.

Conclusion
By unifying data extraction, consumer offset management, and payload correction, Kpow eliminates the need for manual scripts and cross-team ticketing during a production outage. Operators can seamlessly isolate a poison pill, safely skip the consumer offset using scheduled mutations, and repair the data payload in a single, cohesive workflow. This comprehensive approach restores data pipelines rapidly and guarantees that no critical messages are lost.
While these remediation capabilities are incredibly powerful, they must be governed securely. In the final part of this series, Defense in Depth: Unifying RBAC and Data Policies for Transparent Governance, we will explore how organizations can deploy these tools safely in production without exposing sensitive information or violating compliance constraints.
Next steps
Explore Kpow in your own environment with a free 30-day trial.
If you need assistance managing your Kafka environment, reach out to our engineering support team at support@factorhouse.io.